 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Model-Based Clustering with Sequential Monte Carlo
Apr 16, 2026In online clustering problems, there is often a large amount of uncertainty over possible cluster assignments that cannot be resolved until more data are observed. This difficulty is compounded when clusters follow complex distributions, as is the case with text data. Sequential Monte Carlo (SMC) methods give a natural way of representing and updating this uncertainty over time, but have prohibitive memory requirements for large-scale problems. We propose a novel SMC algorithm that decomposes clustering problems into approximately independent subproblems, allowing a more compact representation of the algorithm state. Our approach is motivated by the knowledge base construction problem, and we show that our method is able to accurately and efficiently solve clustering problems in this setting and others where traditional SMC struggles.
Understanding Causality with Large Language Models: Feasibility and Opportunities
Apr 11, 2023
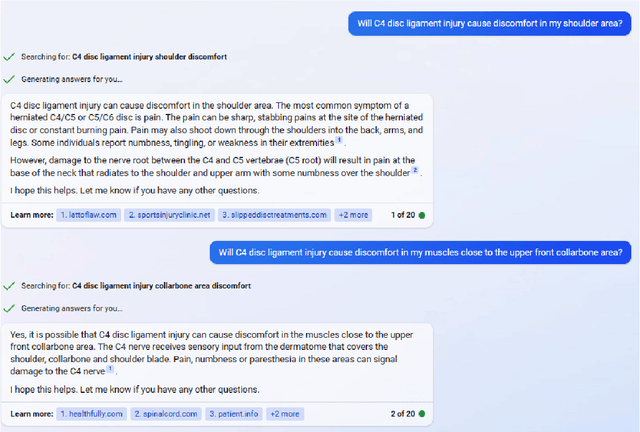
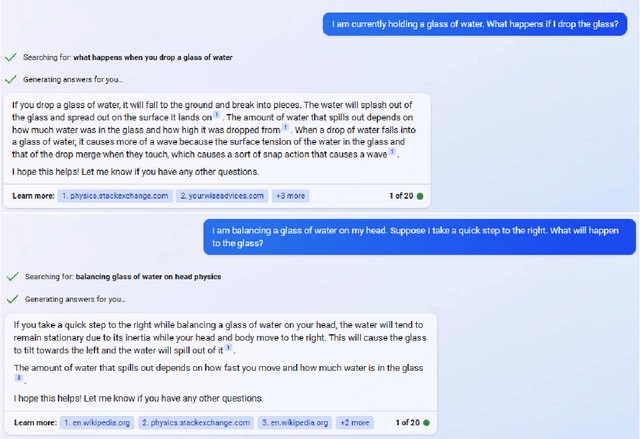
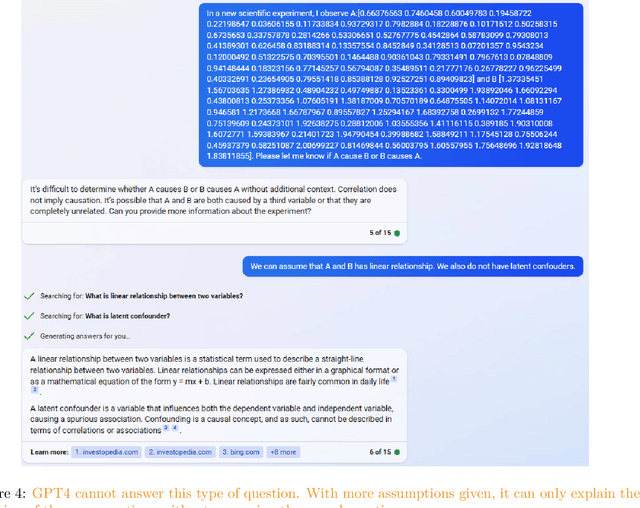
We assess the ability of large language models (LLMs) to answer causal questions by analyzing their strengths and weaknesses against three types of causal question. We believe that current LLMs can answer causal questions with existing causal knowledge as combined domain experts. However, they are not yet able to provide satisfactory answers for discovering new knowledge or for high-stakes decision-making tasks with high precision. We discuss possible future directions and opportunities, such as enabling explicit and implicit causal modules as well as deep causal-aware LLMs. These will not only enable LLMs to answer many different types of causal questions for greater impact but also enable LLMs to be more trustworthy and efficient in general.
A* Sampling
Jan 26, 2015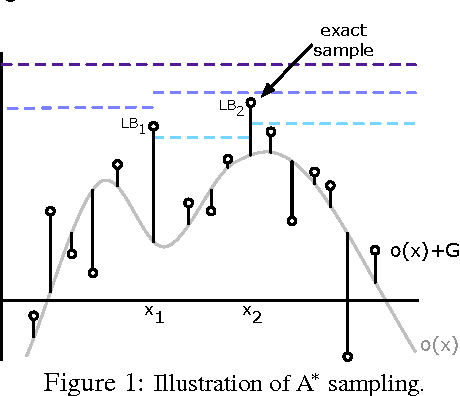
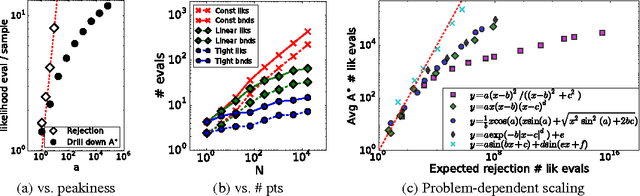
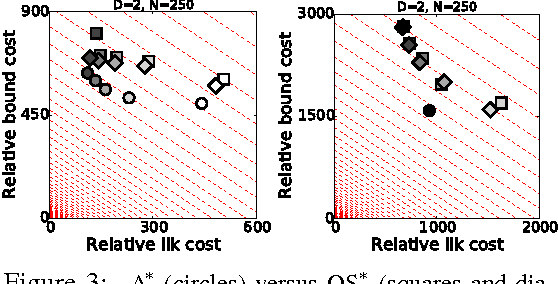
The problem of drawing samples from a discrete distribution can be converted into a discrete optimization problem. In this work, we show how sampling from a continuous distribution can be converted into an optimization problem over continuous space. Central to the method is a stochastic process recently described in mathematical statistics that we call the Gumbel process. We present a new construction of the Gumbel process and A* sampling, a practical generic sampling algorithm that searches for the maximum of a Gumbel process using A* search. We analyze the correctness and convergence time of A* sampling and demonstrate empirically that it makes more efficient use of bound and likelihood evaluations than the most closely related adaptive rejection sampling-based algorithms.
How To Grade a Test Without Knowing the Answers --- A Bayesian Graphical Model for Adaptive Crowdsourcing and Aptitude Testing
Jun 27, 2012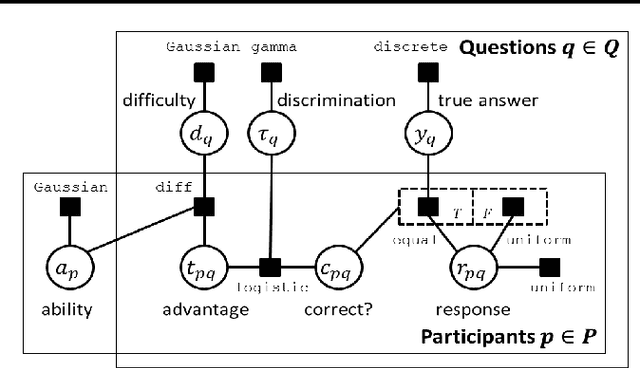
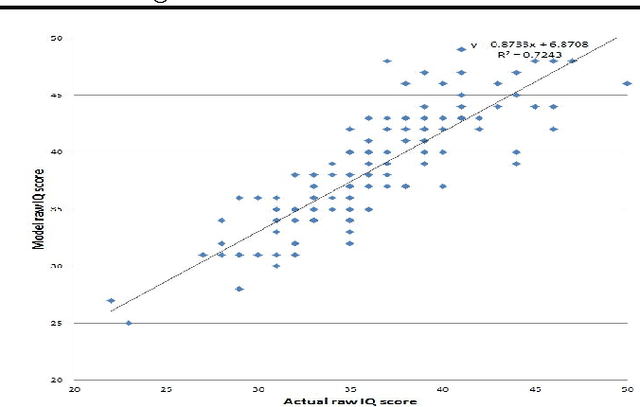
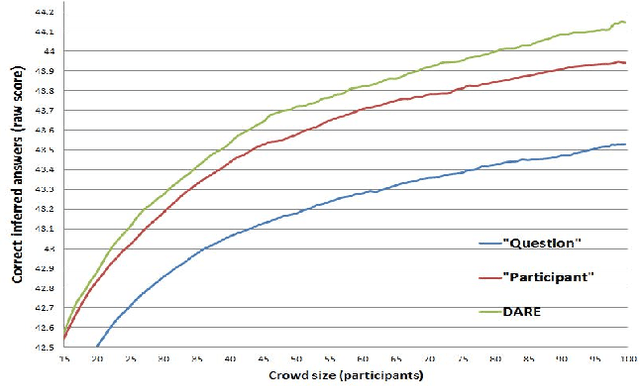
We propose a new probabilistic graphical model that jointly models the difficulties of questions, the abilities of participants and the correct answers to questions in aptitude testing and crowdsourcing settings. We devise an active learning/adaptive testing scheme based on a greedy minimization of expected model entropy, which allows a more efficient resource allocation by dynamically choosing the next question to be asked based on the previous responses. We present experimental results that confirm the ability of our model to infer the required parameters and demonstrate that the adaptive testing scheme requires fewer questions to obtain the same accuracy as a static test scenario.