 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement World Model Learning for LLM-based Agents
Feb 05, 2026Large language models (LLMs) have achieved strong performance in language-centric tasks. However, in agentic settings, LLMs often struggle to anticipate action consequences and adapt to environment dynamics, highlighting the need for world-modeling capabilities in LLM-based agents. We propose Reinforcement World Model Learning (RWML), a self-supervised method that learns action-conditioned world models for LLM-based agents on textual states using sim-to-real gap rewards. Our method aligns simulated next states produced by the model with realized next states observed from the environment, encouraging consistency between internal world simulations and actual environment dynamics in a pre-trained embedding space. Unlike next-state token prediction, which prioritizes token-level fidelity (i.e., reproducing exact wording) over semantic equivalence and can lead to model collapse, our method provides a more robust training signal and is empirically less susceptible to reward hacking than LLM-as-a-judge. We evaluate our method on ALFWorld and $τ^2$ Bench and observe significant gains over the base model, despite being entirely self-supervised. When combined with task-success rewards, our method outperforms direct task-success reward RL by 6.9 and 5.7 points on ALFWorld and $τ^2$ Bench respectively, while matching the performance of expert-data training.
Understanding Causality with Large Language Models: Feasibility and Opportunities
Apr 11, 2023
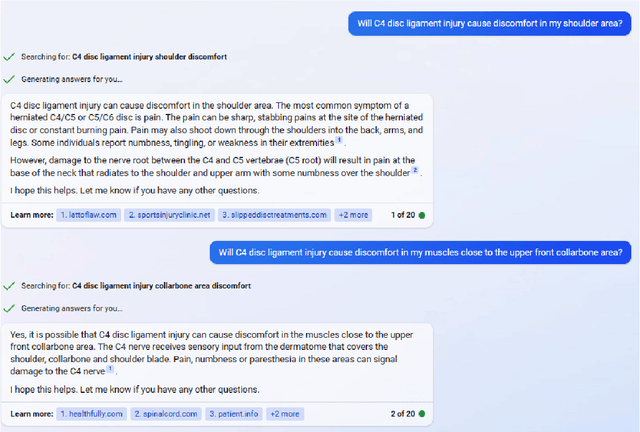
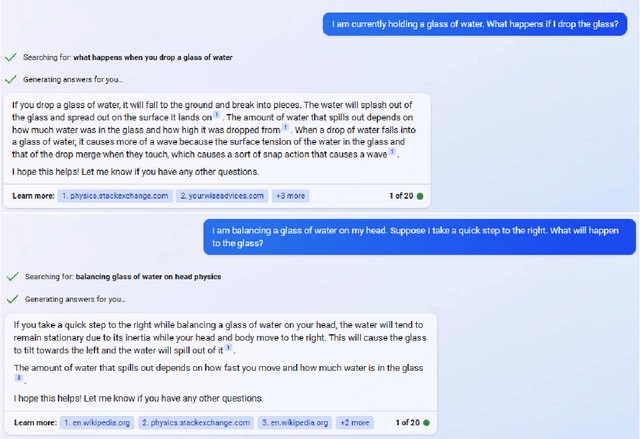
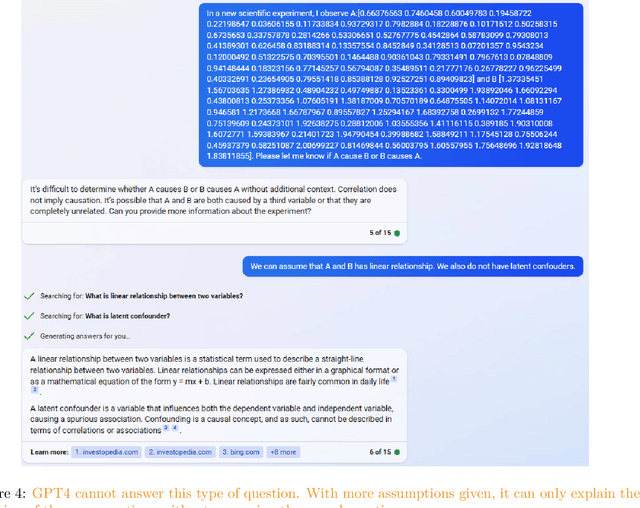
We assess the ability of large language models (LLMs) to answer causal questions by analyzing their strengths and weaknesses against three types of causal question. We believe that current LLMs can answer causal questions with existing causal knowledge as combined domain experts. However, they are not yet able to provide satisfactory answers for discovering new knowledge or for high-stakes decision-making tasks with high precision. We discuss possible future directions and opportunities, such as enabling explicit and implicit causal modules as well as deep causal-aware LLMs. These will not only enable LLMs to answer many different types of causal questions for greater impact but also enable LLMs to be more trustworthy and efficient in general.