 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentForge: Execution-Grounded Multi-Agent LLM Framework for Autonomous Software Engineering
Apr 13, 2026Large language models generate plausible code but cannot verify correctness. Existing multi-agent systems simulate execution or leave verification optional. We introduce execution-grounded verification as a first-class principle: every code change must survive sandboxed execution before propagation. We instantiate this principle in AGENTFORGE, a multi-agent framework where Planner, Coder, Tester, Debugger, and Critic agents coordinate through shared memory and a mandatory Docker sandbox. We formalize software engineering with LLMs as an iterative decision process over repository states, where execution feedback provides a stronger supervision signal than next-token likelihood. AGENTFORGE achieves 40.0\% resolution on SWE-BENCH Lite, outperforming single-agent baselines by 26--28 points. Ablations confirm that execution feedback and role decomposition each independently drive performance. The framework is open-source at https://github.com/raja21068/AutoCodeAI.
Graph Neural Operators for Classification of Spatial Transcriptomics Data
Feb 01, 2023The inception of spatial transcriptomics has allowed improved comprehension of tissue architectures and the disentanglement of complex underlying biological, physiological, and pathological processes through their positional contexts. Recently, these contexts, and by extension the field, have seen much promise and elucidation with the application of graph learning approaches. In particular, neural operators have risen in regards to learning the mapping between infinite-dimensional function spaces. With basic to deep neural network architectures being data-driven, i.e. dependent on quality data for prediction, neural operators provide robustness by offering generalization among different resolutions despite low quality data. Graph neural operators are a variant that utilize graph networks to learn this mapping between function spaces. The aim of this research is to identify robust machine learning architectures that integrate spatial information to predict tissue types. Under this notion, we propose a study incorporating various graph neural network approaches to validate the efficacy of applying neural operators towards prediction of brain regions in mouse brain tissue samples as a proof of concept towards our purpose. We were able to achieve an F1 score of nearly 72% for the graph neural operator approach which outperformed all baseline and other graph network approaches.
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Jul 01, 2020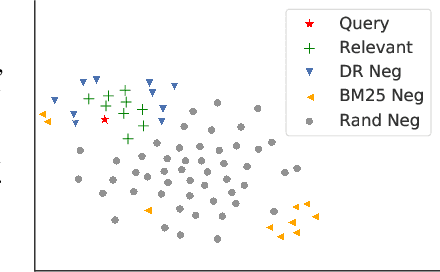
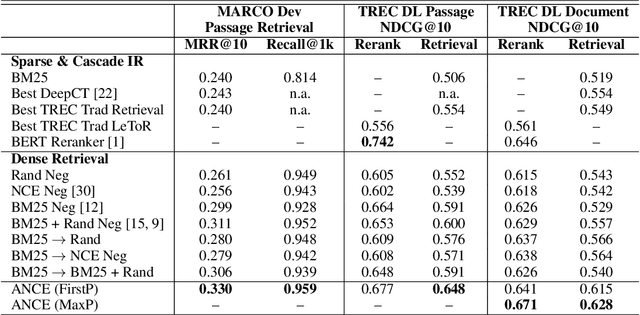
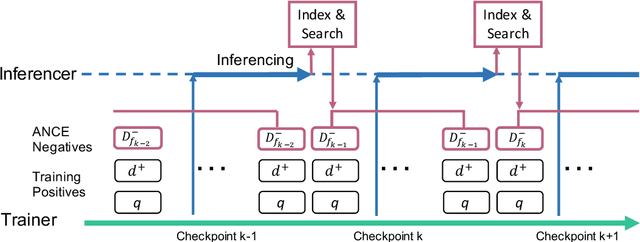

Conducting text retrieval in a dense learned representation space has many intriguing advantages over sparse retrieval. Yet the effectiveness of dense retrieval (DR) often requires combination with sparse retrieval. In this paper, we identify that the main bottleneck is in the training mechanisms, where the negative instances used in training are not representative of the irrelevant documents in testing. This paper presents Approximate nearest neighbor Negative Contrastive Estimation (ANCE), a training mechanism that constructs negatives from an Approximate Nearest Neighbor (ANN) index of the corpus, which is parallelly updated with the learning process to select more realistic negative training instances. This fundamentally resolves the discrepancy between the data distribution used in the training and testing of DR. In our experiments, ANCE boosts the BERT-Siamese DR model to outperform all competitive dense and sparse retrieval baselines. It nearly matches the accuracy of sparse-retrieval-and-BERT-reranking using dot-product in the ANCE-learned representation space and provides almost 100x speed-up.