 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMonitor: A Plug-and-Play Framework for Predictive and Secure Multi-Agent Systems
Aug 27, 2024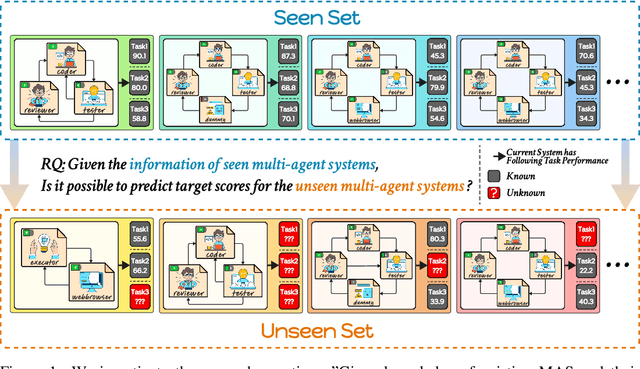
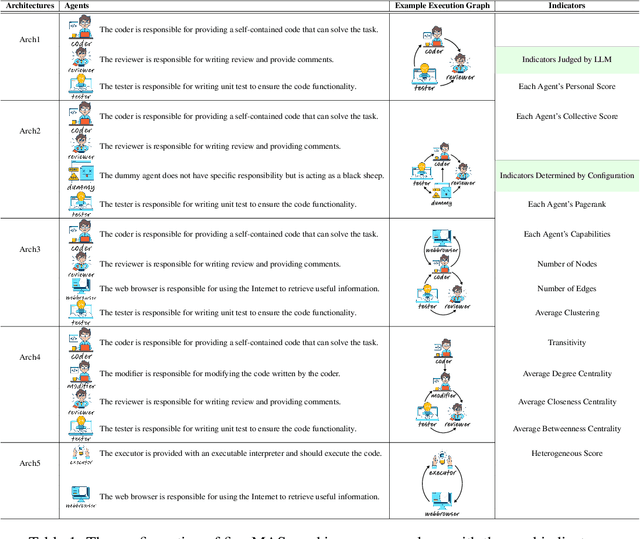
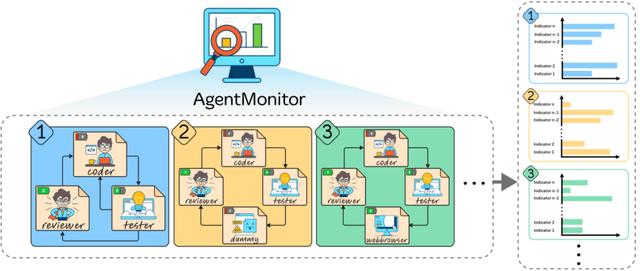
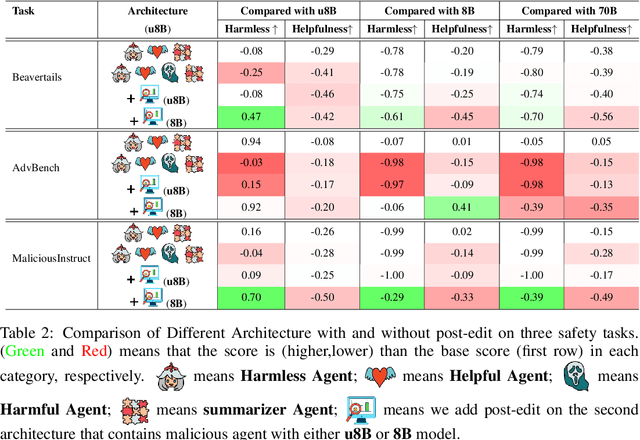
The rapid advancement of large language models (LLMs) has led to the rise of LLM-based agents. Recent research shows that multi-agent systems (MAS), where each agent plays a specific role, can outperform individual LLMs. However, configuring an MAS for a task remains challenging, with performance only observable post-execution. Inspired by scaling laws in LLM development, we investigate whether MAS performance can be predicted beforehand. We introduce AgentMonitor, a framework that integrates at the agent level to capture inputs and outputs, transforming them into statistics for training a regression model to predict task performance. Additionally, it can further apply real-time corrections to address security risks posed by malicious agents, mitigating negative impacts and enhancing MAS security. Experiments demonstrate that an XGBoost model achieves a Spearman correlation of 0.89 in-domain and 0.58 in more challenging scenarios. Furthermore, using AgentMonitor reduces harmful content by 6.2% and increases helpful content by 1.8% on average, enhancing safety and reliability. Code is available at \url{https://github.com/chanchimin/AgentMonitor}.
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Aug 14, 2023Text evaluation has historically posed significant challenges, often demanding substantial labor and time cost. With the emergence of large language models (LLMs), researchers have explored LLMs' potential as alternatives for human evaluation. While these single-agent-based approaches show promise, experimental results suggest that further advancements are needed to bridge the gap between their current effectiveness and human-level evaluation quality. Recognizing that best practices of human evaluation processes often involve multiple human annotators collaborating in the evaluation, we resort to a multi-agent debate framework, moving beyond single-agent prompting strategies. The multi-agent-based approach enables a group of LLMs to synergize with an array of intelligent counterparts, harnessing their distinct capabilities and expertise to enhance efficiency and effectiveness in handling intricate tasks. In this paper, we construct a multi-agent referee team called ChatEval to autonomously discuss and evaluate the quality of generated responses from different models on open-ended questions and traditional natural language generation (NLG) tasks. Our analysis shows that ChatEval transcends mere textual scoring, offering a human-mimicking evaluation process for reliable assessments. Our code is available at https://github.com/chanchimin/ChatEval.