 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Driven Deep Learning for Enhanced Protein-Specific Molecular Generation
Mar 11, 2025In recent years, deep learning techniques have made significant strides in molecular generation for specific targets, driving advancements in drug discovery. However, existing molecular generation methods present significant limitations: those operating at the atomic level often lack synthetic feasibility, drug-likeness, and interpretability, while fragment-based approaches frequently overlook comprehensive factors that influence protein-molecule interactions. To address these challenges, we propose a novel fragment-based molecular generation framework tailored for specific proteins. Our method begins by constructing a protein subpocket and molecular arm concept-based neural network, which systematically integrates interaction force information and geometric complementarity to sample molecular arms for specific protein subpockets. Subsequently, we introduce a diffusion model to generate molecular backbones that connect these arms, ensuring structural integrity and chemical diversity. Our approach significantly improves synthetic feasibility and binding affinity, with a 4% increase in drug-likeness and a 6% improvement in synthetic feasibility. Furthermore, by integrating explicit interaction data through a concept-based model, our framework enhances interpretability, offering valuable insights into the molecular design process.
Transforming Indoor Localization: Advanced Transformer Architecture for NLOS Dominated Wireless Environments with Distributed Sensors
Jan 14, 2025Indoor localization in challenging non-line-of-sight (NLOS) environments often leads to mediocre accuracy with traditional approaches. Deep learning (DL) has been applied to tackle these challenges; however, many DL approaches overlook computational complexity, especially for floating-point operations (FLOPs), making them unsuitable for resource-limited devices. Transformer-based models have achieved remarkable success in natural language processing (NLP) and computer vision (CV) tasks, motivating their use in wireless applications. However, their use in indoor localization remains nascent, and directly applying Transformers for indoor localization can be both computationally intensive and exhibit limitations in accuracy. To address these challenges, in this work, we introduce a novel tokenization approach, referred to as Sensor Snapshot Tokenization (SST), which preserves variable-specific representations of power delay profile (PDP) and enhances attention mechanisms by effectively capturing multi-variate correlation. Complementing this, we propose a lightweight Swish-Gated Linear Unit-based Transformer (L-SwiGLU Transformer) model, designed to reduce computational complexity without compromising localization accuracy. Together, these contributions mitigate the computational burden and dependency on large datasets, making Transformer models more efficient and suitable for resource-constrained scenarios. The proposed tokenization method enables the Vanilla Transformer to achieve a 90th percentile positioning error of 0.388 m in a highly NLOS indoor factory, surpassing conventional tokenization methods. The L-SwiGLU ViT further reduces the error to 0.355 m, achieving an 8.51% improvement. Additionally, the proposed model outperforms a 14.1 times larger model with a 46.13% improvement, underscoring its computational efficiency.
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
Jul 23, 2024



With advancements in self-supervised learning, the availability of trillions tokens in a pre-training corpus, instruction fine-tuning, and the development of large Transformers with billions of parameters, large language models (LLMs) are now capable of generating factual and coherent responses to human queries. However, the mixed quality of training data can lead to the generation of undesired responses, presenting a significant challenge. Over the past two years, various methods have been proposed from different perspectives to enhance LLMs, particularly in aligning them with human expectation. Despite these efforts, there has not been a comprehensive survey paper that categorizes and details these approaches. In this work, we aim to address this gap by categorizing these papers into distinct topics and providing detailed explanations of each alignment method, thereby helping readers gain a thorough understanding of the current state of the field.
PAFT: A Parallel Training Paradigm for Effective LLM Fine-Tuning
Jun 25, 2024



Large language models (LLMs) have shown remarkable abilities in diverse natural language processing (NLP) tasks. The LLMs generally undergo supervised fine-tuning (SFT) followed by preference alignment to be usable in downstream applications. However, this sequential training pipeline leads to alignment tax that degrades the LLM performance. This paper introduces PAFT, a new PArallel training paradigm for effective LLM Fine-Tuning, which independently performs SFT and preference alignment (e.g., DPO and ORPO, etc.) with the same pre-trained model on respective datasets. The model produced by SFT and the model from preference alignment are then merged into a final model by parameter fusing for use in downstream applications. This work reveals important findings that preference alignment like DPO naturally results in a sparse model while SFT leads to a natural dense model which needs to be sparsified for effective model merging. This paper introduces an effective interference resolution which reduces the redundancy by sparsifying the delta parameters. The LLM resulted from the new training paradigm achieved Rank #1 on the HuggingFace Open LLM Leaderboard. Comprehensive evaluation shows the effectiveness of the parallel training paradigm.
One-Shot Imitation Filming of Human Motion Videos
Dec 23, 2019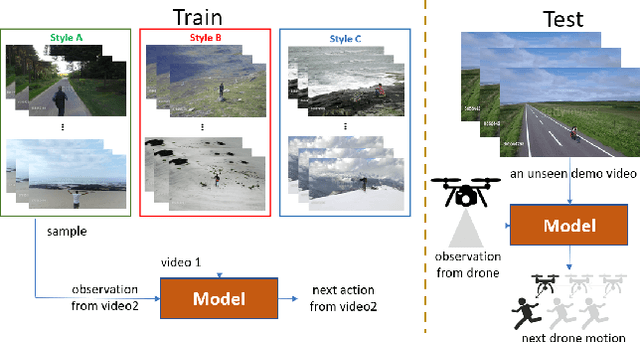


Imitation learning has been applied to mimic the operation of a human cameraman in several autonomous cinematography systems. To imitate different filming styles, existing methods train multiple models, where each model handles a particular style and requires a significant number of training samples. As a result, existing methods can hardly generalize to unseen styles. In this paper, we propose a framework, which can imitate a filming style by "seeing" only a single demonstration video of the same style, i.e., one-shot imitation filming. This is done by two key enabling techniques: 1) feature extraction of the filming style from the demo video, and 2) filming style transfer from the demo video to the new situation. We implement the approach with deep neural network and deploy it to a 6 degrees of freedom (DOF) real drone cinematography system by first predicting the future camera motions, and then converting them to the drone's control commands via an odometer. Our experimental results on extensive datasets and showcases exhibit significant improvements in our approach over conventional baselines and our approach can successfully mimic the footage with an unseen style.
REDBEE: A Visual-Inertial Drone System for Real-Time Moving Object Detection
Dec 26, 2017
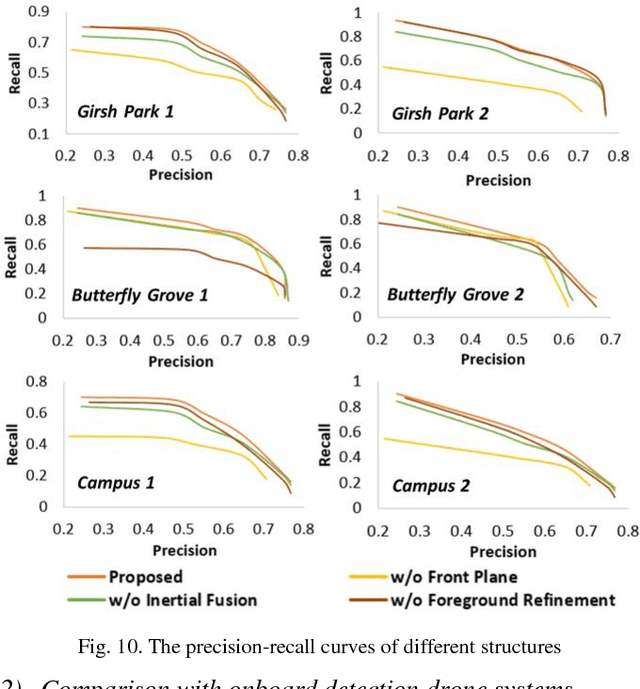
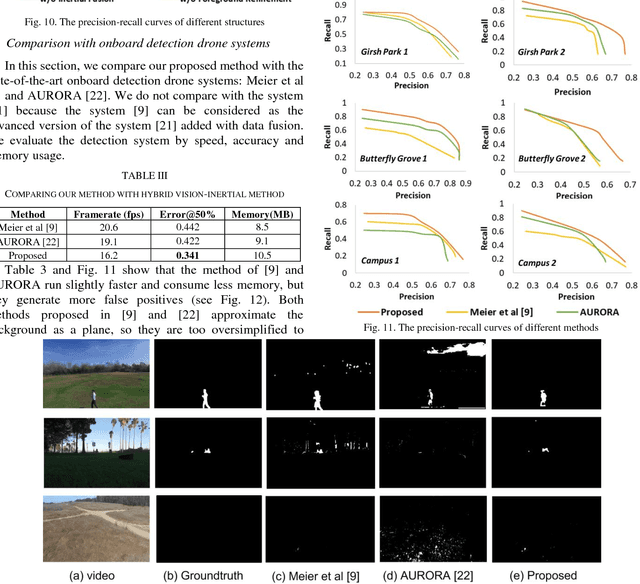

Aerial surveillance and monitoring demand both real-time and robust motion detection from a moving camera. Most existing techniques for drones involve sending a video data streams back to a ground station with a high-end desktop computer or server. These methods share one major drawback: data transmission is subjected to considerable delay and possible corruption. Onboard computation can not only overcome the data corruption problem but also increase the range of motion. Unfortunately, due to limited weight-bearing capacity, equipping drones with computing hardware of high processing capability is not feasible. Therefore, developing a motion detection system with real-time performance and high accuracy for drones with limited computing power is highly desirable. In this paper, we propose a visual-inertial drone system for real-time motion detection, namely REDBEE, that helps overcome challenges in shooting scenes with strong parallax and dynamic background. REDBEE, which can run on the state-of-the-art commercial low-power application processor (e.g. Snapdragon Flight board used for our prototype drone), achieves real-time performance with high detection accuracy. The REDBEE system overcomes obstacles in shooting scenes with strong parallax through an inertial-aided dual-plane homography estimation; it solves the issues in shooting scenes with dynamic background by distinguishing the moving targets through a probabilistic model based on spatial, temporal, and entropy consistency. The experiments are presented which demonstrate that our system obtains greater accuracy when detecting moving targets in outdoor environments than the state-of-the-art real-time onboard detection systems.
Local Feature Descriptor Learning with Adaptive Siamese Network
Jun 16, 2017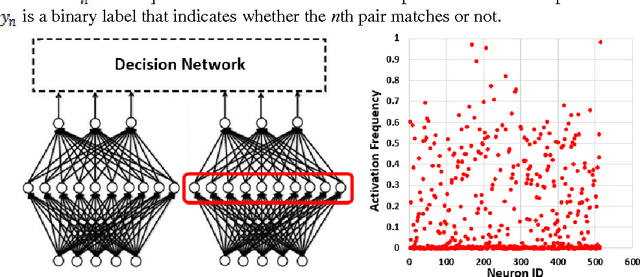
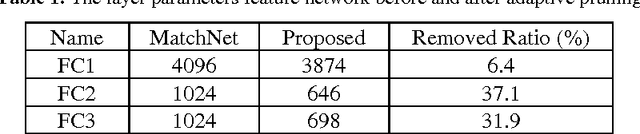

Although the recent progress in the deep neural network has led to the development of learnable local feature descriptors, there is no explicit answer for estimation of the necessary size of a neural network. Specifically, the local feature is represented in a low dimensional space, so the neural network should have more compact structure. The small networks required for local feature descriptor learning may be sensitive to initial conditions and learning parameters and more likely to become trapped in local minima. In order to address the above problem, we introduce an adaptive pruning Siamese Architecture based on neuron activation to learn local feature descriptors, making the network more computationally efficient with an improved recognition rate over more complex networks. Our experiments demonstrate that our learned local feature descriptors outperform the state-of-art methods in patch matching.