Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Emerges by Colorizing Videos
Paper and Code

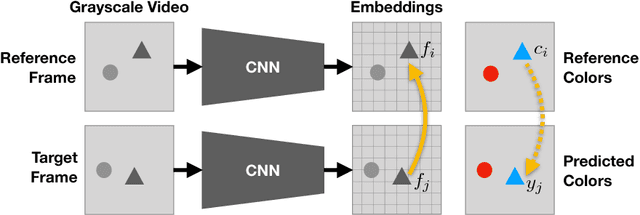


We use large amounts of unlabeled video to learn models for visual tracking without manual human supervision. We leverage the natural temporal coherency of color to create a model that learns to colorize gray-scale videos by copying colors from a reference frame. Quantitative and qualitative experiments suggest that this task causes the model to automatically learn to track visual regions. Although the model is trained without any ground-truth labels, our method learns to track well enough to outperform the latest methods based on optical flow. Moreover, our results suggest that failures to track are correlated with failures to colorize, indicating that advancing video colorization may further improve self-supervised visual tracking.
* ECCV 2018. Blog post:
https://ai.googleblog.com/2018/06/self-supervised-tracking-via-video.html
View paper on