 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIB is Half Bayes
Nov 17, 2020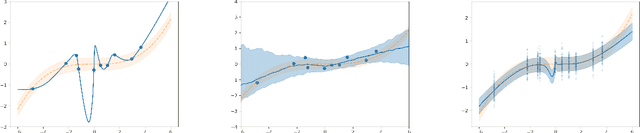
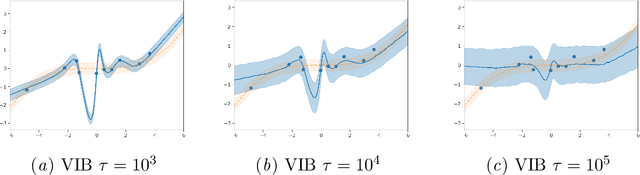

In discriminative settings such as regression and classification there are two random variables at play, the inputs X and the targets Y. Here, we demonstrate that the Variational Information Bottleneck can be viewed as a compromise between fully empirical and fully Bayesian objectives, attempting to minimize the risks due to finite sampling of Y only. We argue that this approach provides some of the benefits of Bayes while requiring only some of the work.
Text Segmentation based on Semantic Word Embeddings
Mar 18, 2015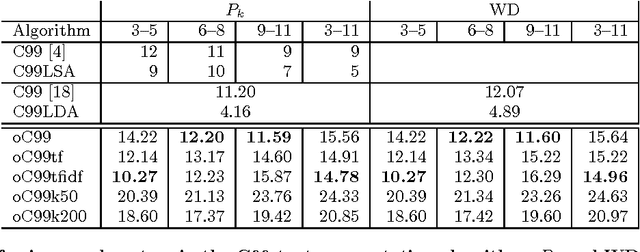
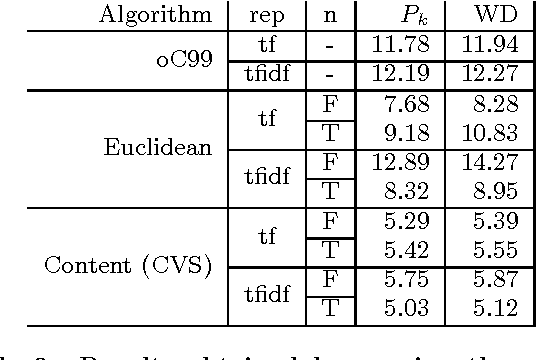
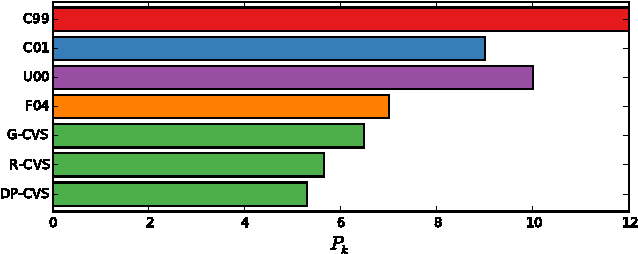
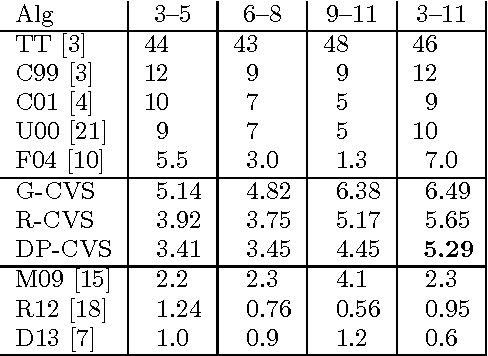
We explore the use of semantic word embeddings in text segmentation algorithms, including the C99 segmentation algorithm and new algorithms inspired by the distributed word vector representation. By developing a general framework for discussing a class of segmentation objectives, we study the effectiveness of greedy versus exact optimization approaches and suggest a new iterative refinement technique for improving the performance of greedy strategies. We compare our results to known benchmarks, using known metrics. We demonstrate state-of-the-art performance for an untrained method with our Content Vector Segmentation (CVS) on the Choi test set. Finally, we apply the segmentation procedure to an in-the-wild dataset consisting of text extracted from scholarly articles in the arXiv.org database.