 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific production in the era of Large Language Models
Jan 19, 2026Large Language Models (LLMs) are rapidly reshaping scientific research. We analyze these changes in multiple, large-scale datasets with 2.1M preprints, 28K peer review reports, and 246M online accesses to scientific documents. We find: 1) scientists adopting LLMs to draft manuscripts demonstrate a large increase in paper production, ranging from 23.7-89.3% depending on scientific field and author background, 2) LLM use has reversed the relationship between writing complexity and paper quality, leading to an influx of manuscripts that are linguistically complex but substantively underwhelming, and 3) LLM adopters access and cite more diverse prior work, including books and younger, less-cited documents. These findings highlight a stunning shift in scientific production that will likely require a change in how journals, funding agencies, and tenure committees evaluate scientific works.
* This is the author's version of the work. The definitive version was published in Science on 18 Dec 2025, DOI: 10.1126/science.adw3000. Link to the Final Published Version: https://www.science.org/doi/10.1126/science.adw3000
Attention-based Quantum Tomography
Jun 22, 2020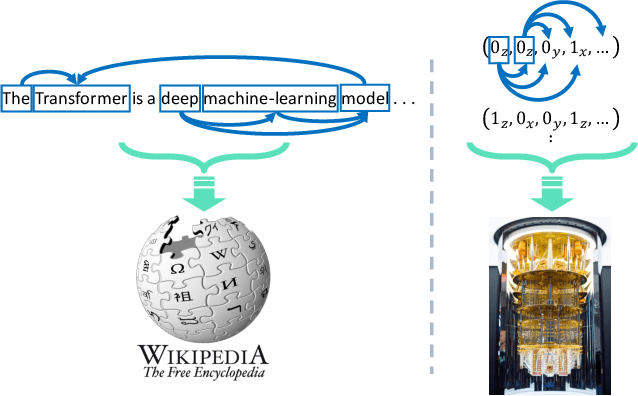
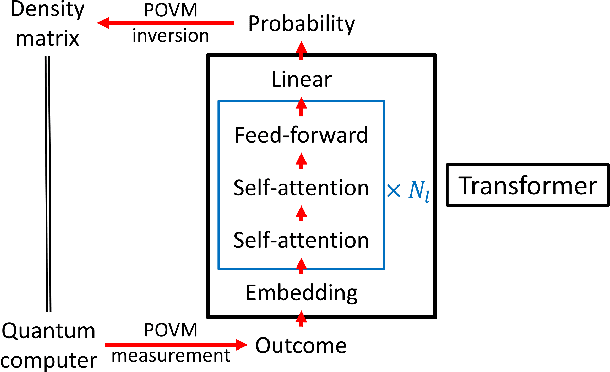
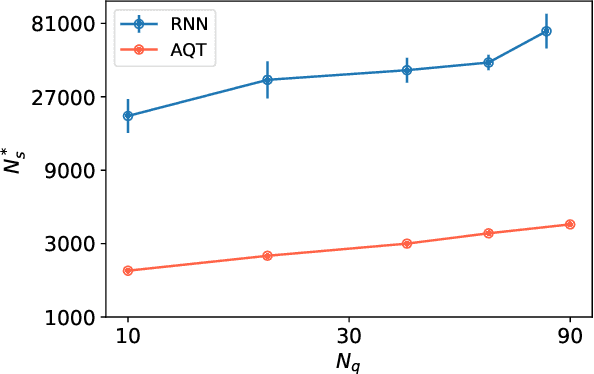
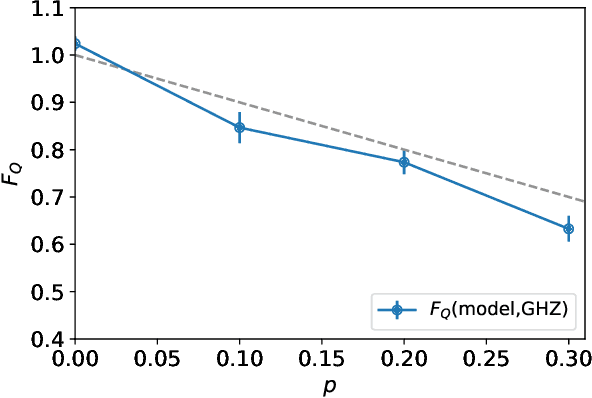
With rapid progress across platforms for quantum systems, the problem of many-body quantum state reconstruction for noisy quantum states becomes an important challenge. Recent works found promise in recasting the problem of quantum state reconstruction to learning the probability distribution of quantum state measurement vectors using generative neural network models. Here we propose the "Attention-based Quantum Tomography" (AQT), a quantum state reconstruction using an attention mechanism-based generative network that learns the mixed state density matrix of a noisy quantum state. The AQT is based on the model proposed in "Attention is all you need" by Vishwani et al (2017) that is designed to learn long-range correlations in natural language sentences and thereby outperform previous natural language processing models. We demonstrate not only that AQT outperforms earlier neural-network-based quantum state reconstruction on identical tasks but that AQT can accurately reconstruct the density matrix associated with a noisy quantum state experimentally realized in an IBMQ quantum computer. We speculate the success of the AQT stems from its ability to model quantum entanglement across the entire quantum system much as the attention model for natural language processing captures the correlations among words in a sentence.
Text Segmentation based on Semantic Word Embeddings
Mar 18, 2015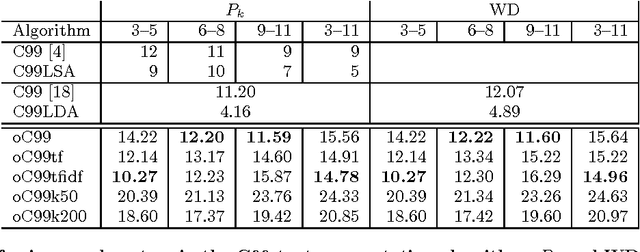
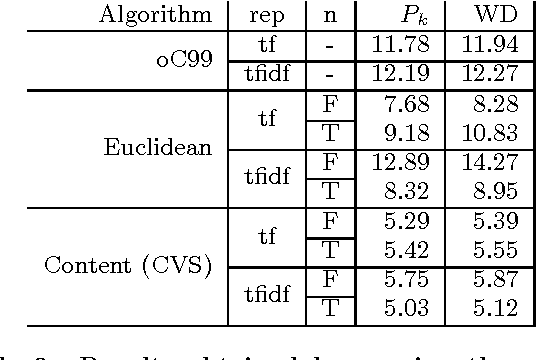
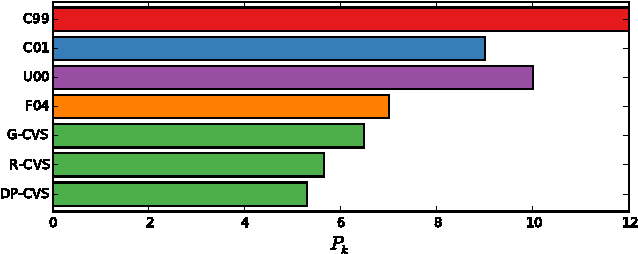
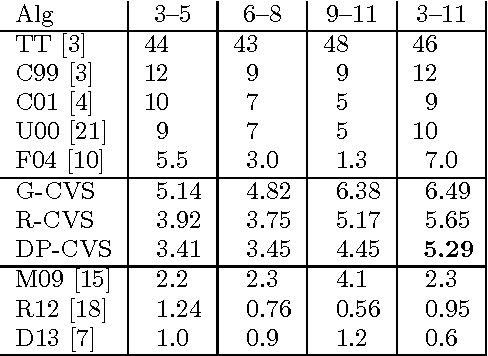
We explore the use of semantic word embeddings in text segmentation algorithms, including the C99 segmentation algorithm and new algorithms inspired by the distributed word vector representation. By developing a general framework for discussing a class of segmentation objectives, we study the effectiveness of greedy versus exact optimization approaches and suggest a new iterative refinement technique for improving the performance of greedy strategies. We compare our results to known benchmarks, using known metrics. We demonstrate state-of-the-art performance for an untrained method with our Content Vector Segmentation (CVS) on the Choi test set. Finally, we apply the segmentation procedure to an in-the-wild dataset consisting of text extracted from scholarly articles in the arXiv.org database.
Mapping Subsets of Scholarly Information
Dec 11, 2003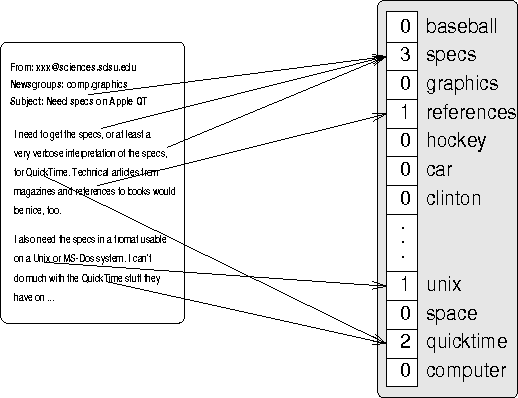
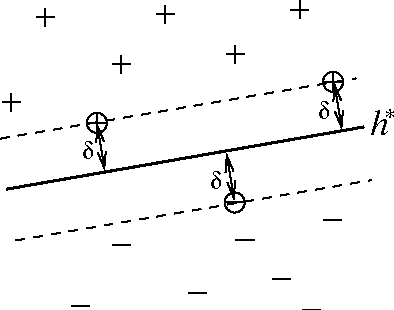
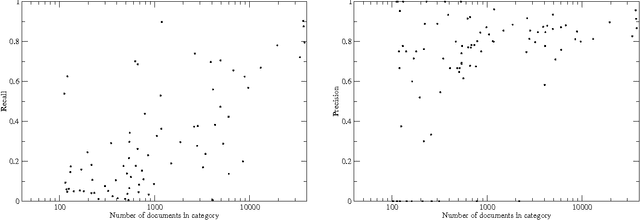
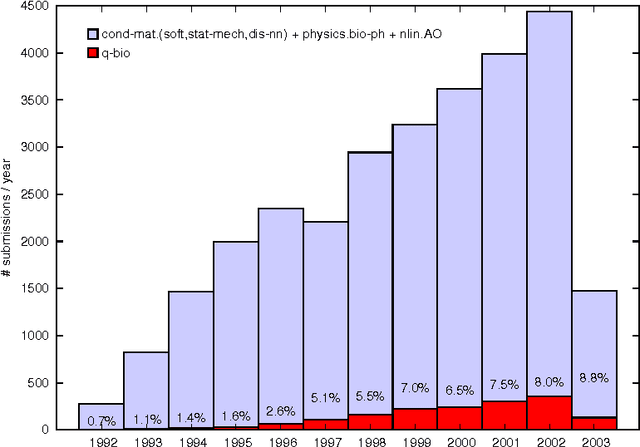
We illustrate the use of machine learning techniques to analyze, structure, maintain, and evolve a large online corpus of academic literature. An emerging field of research can be identified as part of an existing corpus, permitting the implementation of a more coherent community structure for its practitioners.