 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsequences of Misaligned AI
Feb 07, 2021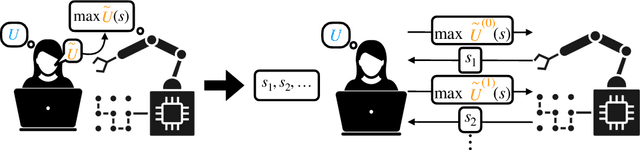

AI systems often rely on two key components: a specified goal or reward function and an optimization algorithm to compute the optimal behavior for that goal. This approach is intended to provide value for a principal: the user on whose behalf the agent acts. The objectives given to these agents often refer to a partial specification of the principal's goals. We consider the cost of this incompleteness by analyzing a model of a principal and an agent in a resource constrained world where the $L$ attributes of the state correspond to different sources of utility for the principal. We assume that the reward function given to the agent only has support on $J < L$ attributes. The contributions of our paper are as follows: 1) we propose a novel model of an incomplete principal-agent problem from artificial intelligence; 2) we provide necessary and sufficient conditions under which indefinitely optimizing for any incomplete proxy objective leads to arbitrarily low overall utility; and 3) we show how modifying the setup to allow reward functions that reference the full state or allowing the principal to update the proxy objective over time can lead to higher utility solutions. The results in this paper argue that we should view the design of reward functions as an interactive and dynamic process and identifies a theoretical scenario where some degree of interactivity is desirable.
Multi-Principal Assistance Games: Definition and Collegial Mechanisms
Dec 29, 2020We introduce the concept of a multi-principal assistance game (MPAG), and circumvent an obstacle in social choice theory, Gibbard's theorem, by using a sufficiently collegial preference inference mechanism. In an MPAG, a single agent assists N human principals who may have widely different preferences. MPAGs generalize assistance games, also known as cooperative inverse reinforcement learning games. We analyze in particular a generalization of apprenticeship learning in which the humans first perform some work to obtain utility and demonstrate their preferences, and then the robot acts to further maximize the sum of human payoffs. We show in this setting that if the game is sufficiently collegial, i.e. if the humans are responsible for obtaining a sufficient fraction of the rewards through their own actions, then their preferences are straightforwardly revealed through their work. This revelation mechanism is non-dictatorial, does not limit the possible outcomes to two alternatives, and is dominant-strategy incentive-compatible.
Multi-Principal Assistance Games
Jul 19, 2020
Assistance games (also known as cooperative inverse reinforcement learning games) have been proposed as a model for beneficial AI, wherein a robotic agent must act on behalf of a human principal but is initially uncertain about the humans payoff function. This paper studies multi-principal assistance games, which cover the more general case in which the robot acts on behalf of N humans who may have widely differing payoffs. Impossibility theorems in social choice theory and voting theory can be applied to such games, suggesting that strategic behavior by the human principals may complicate the robots task in learning their payoffs. We analyze in particular a bandit apprentice game in which the humans act first to demonstrate their individual preferences for the arms and then the robot acts to maximize the sum of human payoffs. We explore the extent to which the cost of choosing suboptimal arms reduces the incentive to mislead, a form of natural mechanism design. In this context we propose a social choice method that uses shared control of a system to combine preference inference with social welfare optimization.