 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-Level Cooperation in Hierarchical Reinforcement Learning
Paper and Code
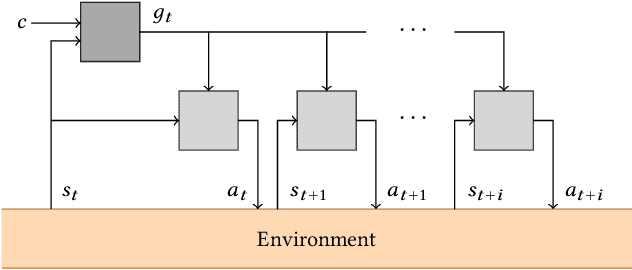
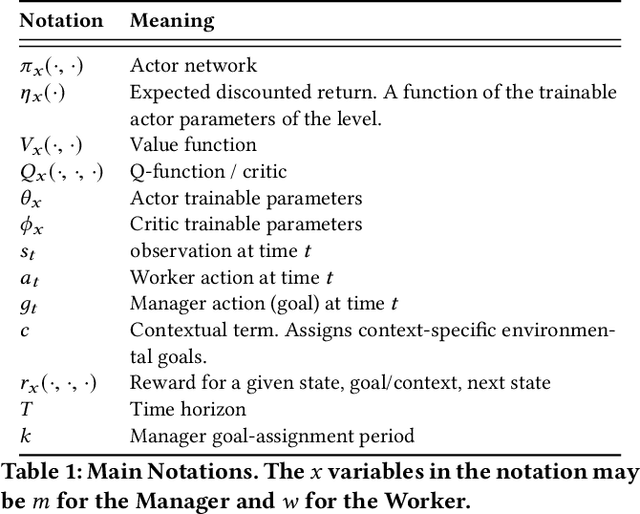


This article presents a novel algorithm for promoting cooperation between internal actors in a goal-conditioned hierarchical reinforcement learning (HRL) policy. Current techniques for HRL policy optimization treat the higher and lower level policies as separate entities which are trained to maximize different objective functions, rendering the HRL problem formulation more similar to a general sum game than a single-agent task. Within this setting, we hypothesize that improved cooperation between the internal agents of a hierarchy can simplify the credit assignment problem from the perspective of the high-level policies, thereby leading to significant improvements to training in situations where intricate sets of action primitives must be performed to yield improvements in performance. In order to promote cooperation within this setting, we propose the inclusion of a connected gradient term to the gradient computations of the higher level policies. Our method is demonstrated to achieve superior results to existing techniques in a set of difficult long time horizon tasks.