 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood Learning of Latent Dynamics Without Reconstruction
May 29, 2025We introduce a novel unsupervised learning method for time series data with latent dynamical structure: the recognition-parametrized Gaussian state space model (RP-GSSM). The RP-GSSM is a probabilistic model that learns Markovian Gaussian latents explaining statistical dependence between observations at different time steps, combining the intuition of contrastive methods with the flexible tools of probabilistic generative models. Unlike contrastive approaches, the RP-GSSM is a valid probabilistic model learned via maximum likelihood. Unlike generative approaches, the RP-GSSM has no need for an explicit network mapping from latents to observations, allowing it to focus model capacity on inference of latents. The model is both tractable and expressive: it admits exact inference thanks to its jointly Gaussian latent prior, while maintaining expressivity with an arbitrarily nonlinear neural network link between observations and latents. These qualities allow the RP-GSSM to learn task-relevant latents without ad-hoc regularization, auxiliary losses, or optimizer scheduling. We show how this approach outperforms alternatives on problems that include learning nonlinear stochastic dynamics from video, with or without background distractors. Our results position the RP-GSSM as a useful foundation model for a variety of downstream applications.
Is there Value in Reinforcement Learning?
May 07, 2025Action-values play a central role in popular Reinforcement Learing (RL) models of behavior. Yet, the idea that action-values are explicitly represented has been extensively debated. Critics had therefore repeatedly suggested that policy-gradient (PG) models should be favored over value-based (VB) ones, as a potential solution for this dilemma. Here we argue that this solution is unsatisfying. This is because PG methods are not, in fact, "Value-free" -- while they do not rely on an explicit representation of Value for acting (stimulus-response mapping), they do require it for learning. Hence, switching to PG models is, per se, insufficient for eliminating Value from models of behavior. More broadly, the requirement for a representation of Value stems from the underlying assumptions regarding the optimization objective posed by the standard RL framework, not from the particular algorithm chosen to solve it. Previous studies mostly took these standard RL assumptions for granted, as part of their conceptualization or problem modeling, while debating the different methods used to optimize it (i.e., PG or VB). We propose that, instead, the focus of the debate should shift to critically evaluating the underlying modeling assumptions. Such evaluation is particularly important from an experimental perspective. Indeed, the very notion of Value must be reconsidered when standard assumptions (e.g., risk neutrality, full-observability, Markovian environment, exponential discounting) are relaxed, as is likely in natural settings. Finally, we use the Value debate as a case study to argue in favor of a more nuanced, algorithmic rather than statistical, view of what constitutes "a model" in cognitive sciences. Our analysis suggests that besides "parametric" statistical complexity, additional aspects such as computational complexity must also be taken into account when evaluating model complexity.
Reinforcement Learning with Large Action Spaces for Neural Machine Translation
Oct 06, 2022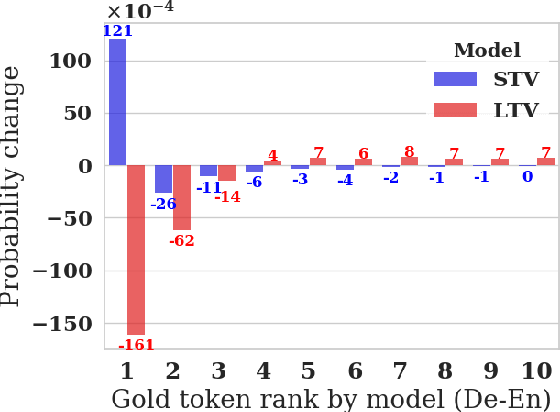
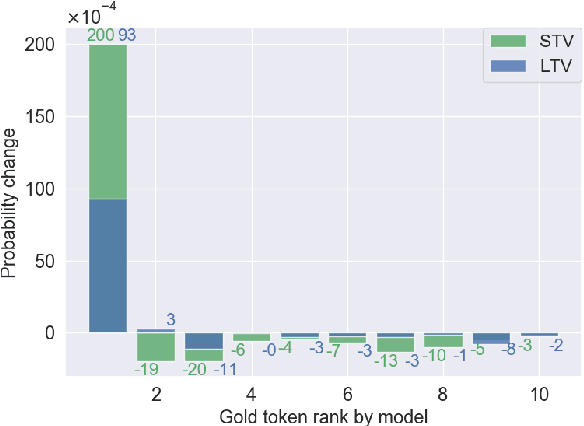
Applying Reinforcement learning (RL) following maximum likelihood estimation (MLE) pre-training is a versatile method for enhancing neural machine translation (NMT) performance. However, recent work has argued that the gains produced by RL for NMT are mostly due to promoting tokens that have already received a fairly high probability in pre-training. We hypothesize that the large action space is a main obstacle to RL's effectiveness in MT, and conduct two sets of experiments that lend support to our hypothesis. First, we find that reducing the size of the vocabulary improves RL's effectiveness. Second, we find that effectively reducing the dimension of the action space without changing the vocabulary also yields notable improvement as evaluated by BLEU, semantic similarity, and human evaluation. Indeed, by initializing the network's final fully connected layer (that maps the network's internal dimension to the vocabulary dimension), with a layer that generalizes over similar actions, we obtain a substantial improvement in RL performance: 1.5 BLEU points on average.
On the Weaknesses of Reinforcement Learning for Neural Machine Translation
Jul 03, 2019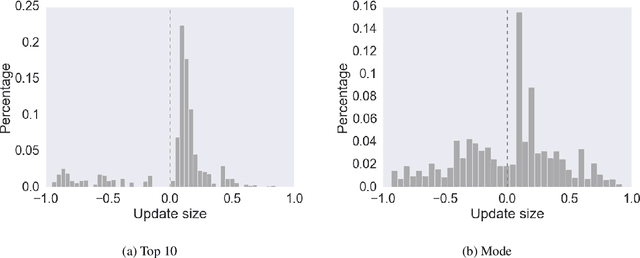

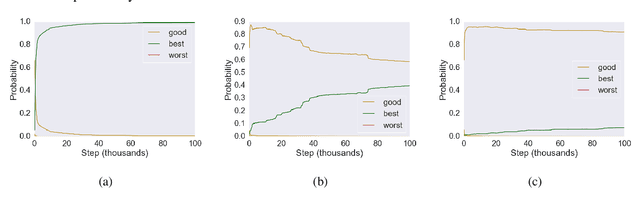
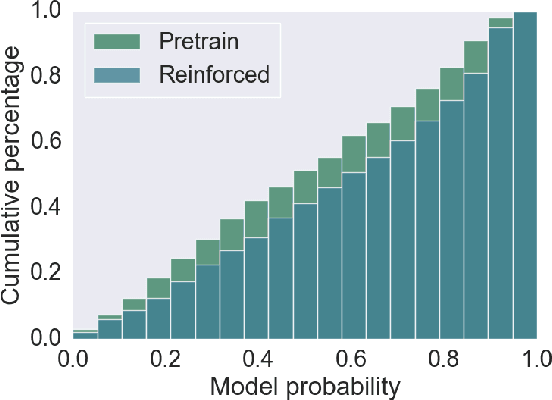
Reinforcement learning (RL) is frequently used to increase performance in text generation tasks, including machine translation (MT), notably through the use of Minimum Risk Training (MRT) and Generative Adversarial Networks (GAN). However, little is known about what and how these methods learn in the context of MT. We prove that one of the most common RL methods for MT does not optimize the expected reward, as well as show that other methods take an infeasibly long time to converge. In fact, our results suggest that RL practices in MT are likely to improve performance only where the pre-trained parameters are already close to yielding the correct translation. Our findings further suggest that observed gains may be due to effects unrelated to the training signal, but rather from changes in the shape of the distribution curve.
DORA The Explorer: Directed Outreaching Reinforcement Action-Selection
Apr 11, 2018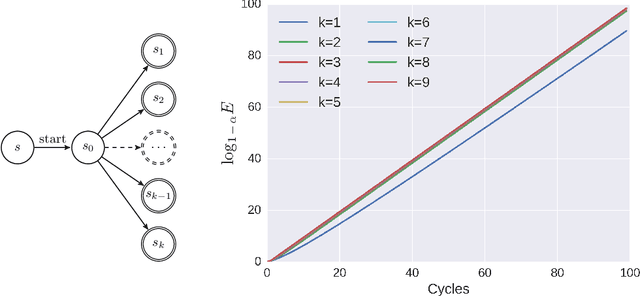
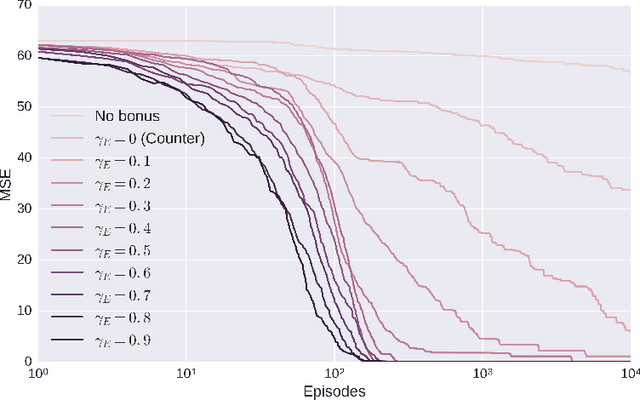
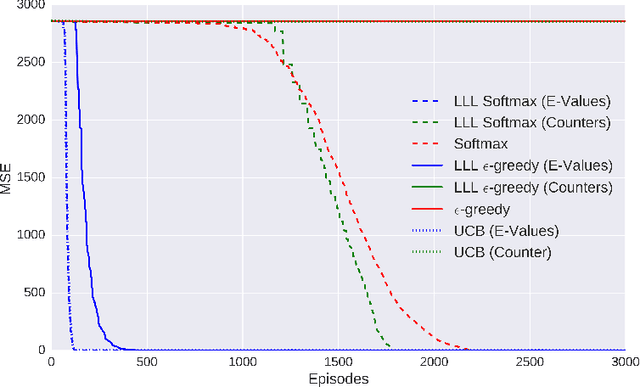
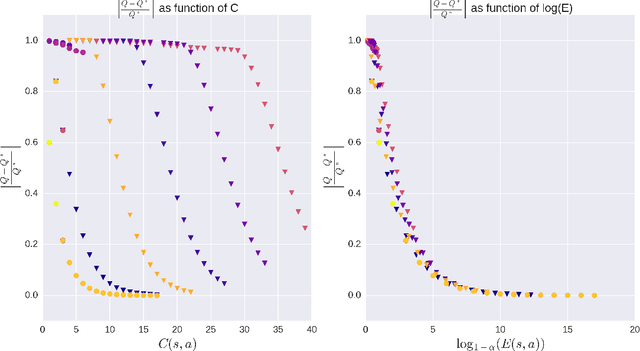
Exploration is a fundamental aspect of Reinforcement Learning, typically implemented using stochastic action-selection. Exploration, however, can be more efficient if directed toward gaining new world knowledge. Visit-counters have been proven useful both in practice and in theory for directed exploration. However, a major limitation of counters is their locality. While there are a few model-based solutions to this shortcoming, a model-free approach is still missing. We propose $E$-values, a generalization of counters that can be used to evaluate the propagating exploratory value over state-action trajectories. We compare our approach to commonly used RL techniques, and show that using $E$-values improves learning and performance over traditional counters. We also show how our method can be implemented with function approximation to efficiently learn continuous MDPs. We demonstrate this by showing that our approach surpasses state of the art performance in the Freeway Atari 2600 game.