 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Weaknesses of Reinforcement Learning for Neural Machine Translation
Paper and Code
Jul 03, 2019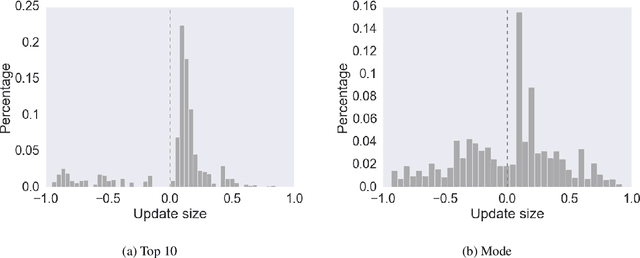

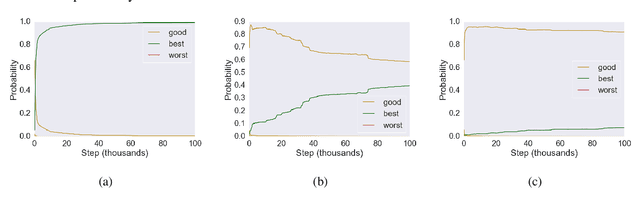
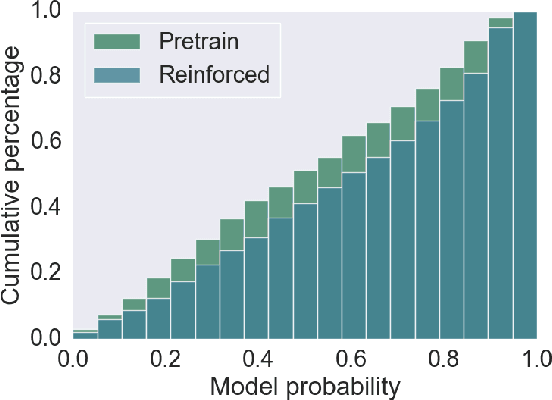
Reinforcement learning (RL) is frequently used to increase performance in text generation tasks, including machine translation (MT), notably through the use of Minimum Risk Training (MRT) and Generative Adversarial Networks (GAN). However, little is known about what and how these methods learn in the context of MT. We prove that one of the most common RL methods for MT does not optimize the expected reward, as well as show that other methods take an infeasibly long time to converge. In fact, our results suggest that RL practices in MT are likely to improve performance only where the pre-trained parameters are already close to yielding the correct translation. Our findings further suggest that observed gains may be due to effects unrelated to the training signal, but rather from changes in the shape of the distribution curve.