 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternet-augmented language models through few-shot prompting for open-domain question answering
Paper and Code
Mar 10, 2022
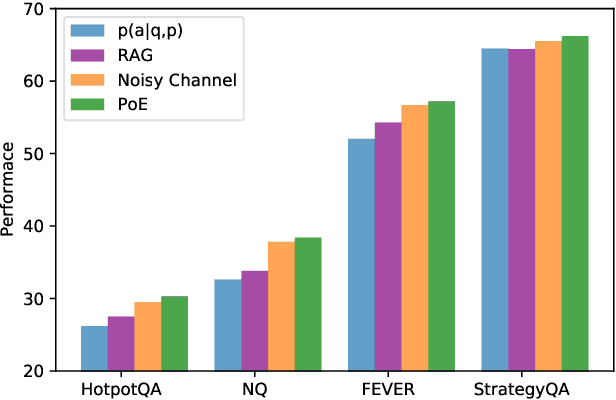
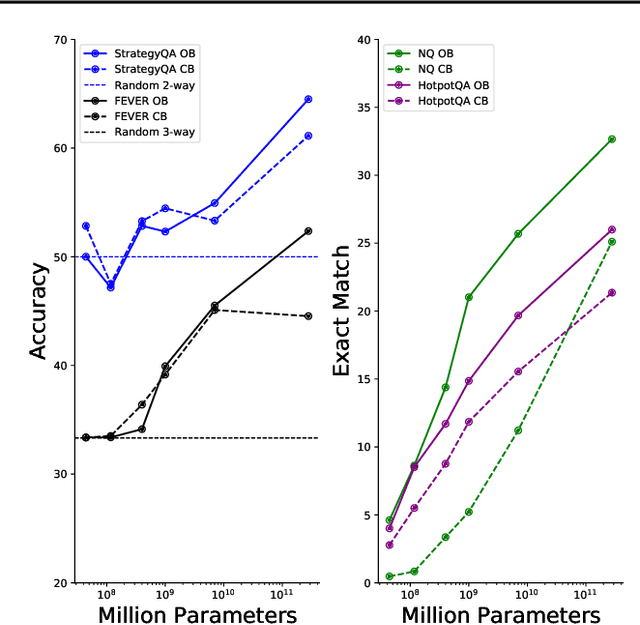
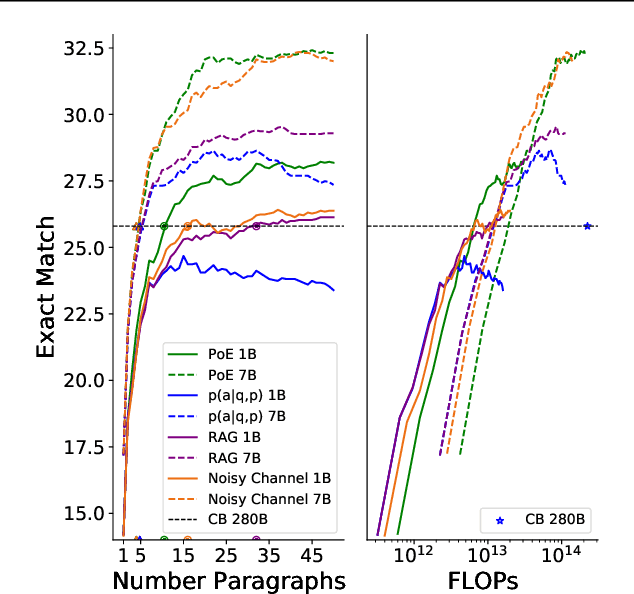
In this work, we aim to capitalize on the unique few-shot capabilities offered by large-scale language models to overcome some of their challenges with respect to grounding to factual and up-to-date information. Motivated by semi-parametric language models, which ground their decisions in external retrieved evidence, we use few-shot prompting to learn to condition language models on information returned from the web using Google Search, a broad and constantly updated knowledge source. Our approach does not involve fine-tuning or learning additional parameters, thus making it applicable to any language model, offering like this a strong baseline. Indeed, we find that language models conditioned on the web surpass performance of closed-book models of similar, or even larger, model sizes in open-domain question answering. Finally, we find that increasing the inference-time compute of models, achieved via using multiple retrieved evidences to generate multiple answers followed by a reranking stage, alleviates generally decreased performance of smaller few-shot language models. All in all, our findings suggest that it might be beneficial to slow down the race towards the biggest model and instead shift the attention towards finding more effective ways to use models, including but not limited to better prompting or increasing inference-time compute.