 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionFlowNet: Learning Motion Representation for Action Recognition
Paper and Code
Feb 16, 2018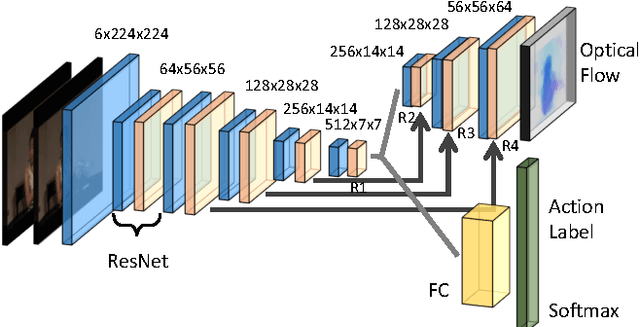
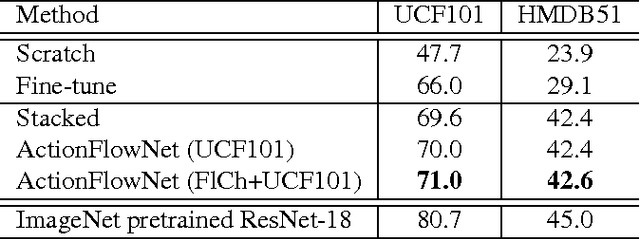
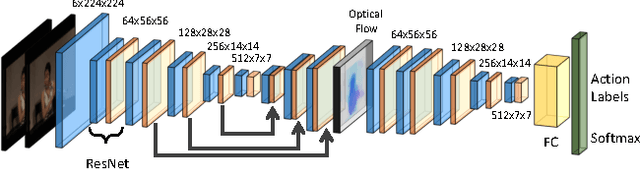
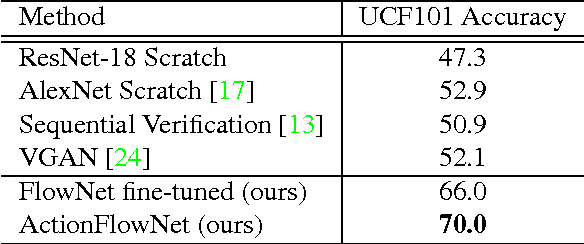
Even with the recent advances in convolutional neural networks (CNN) in various visual recognition tasks, the state-of-the-art action recognition system still relies on hand crafted motion feature such as optical flow to achieve the best performance. We propose a multitask learning model ActionFlowNet to train a single stream network directly from raw pixels to jointly estimate optical flow while recognizing actions with convolutional neural networks, capturing both appearance and motion in a single model. We additionally provide insights to how the quality of the learned optical flow affects the action recognition. Our model significantly improves action recognition accuracy by a large margin 31% compared to state-of-the-art CNN-based action recognition models trained without external large scale data and additional optical flow input. Without pretraining on large external labeled datasets, our model, by well exploiting the motion information, achieves competitive recognition accuracy to the models trained with large labeled datasets such as ImageNet and Sport-1M.