 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Robot Use with Edged or Pointed Objects: A Surrogate Study Assembling a Human Hand Injury Protection Database
Apr 05, 2024



The use of pointed or edged tools or objects is one of the most challenging aspects of today's application of physical human-robot interaction (pHRI). One reason for this is that the severity of harm caused by such edged or pointed impactors is less well studied than for blunt impactors. Consequently, the standards specify well-reasoned force and pressure thresholds for blunt impactors and advise avoiding any edges and corners in contacts. Nevertheless, pointed or edged impactor geometries cannot be completely ruled out in real pHRI applications. For example, to allow edged or pointed tools such as screwdrivers near human operators, the knowledge of injury severity needs to be extended so that robot integrators can perform well-reasoned, time-efficient risk assessments. In this paper, we provide the initial datasets on injury prevention for the human hand based on drop tests with surrogates for the human hand, namely pig claws and chicken drumsticks. We then demonstrate the ease and efficiency of robot use using the dataset for contact on two examples. Finally, our experiments provide a set of injuries that may also be expected for human subjects under certain robot mass-velocity constellations in collisions. To extend this work, testing on human samples and a collaborative effort from research institutes worldwide is needed to create a comprehensive human injury avoidance database for any pHRI scenario and thus for safe pHRI applications including edged and pointed geometries.
ActionFlowNet: Learning Motion Representation for Action Recognition
Feb 16, 2018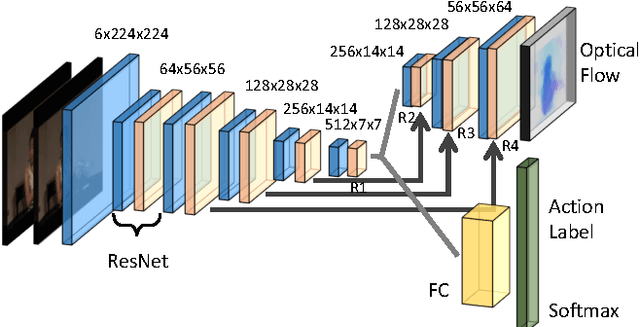
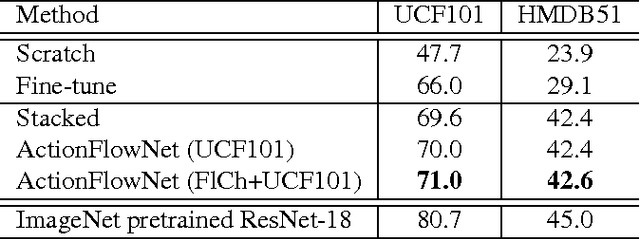
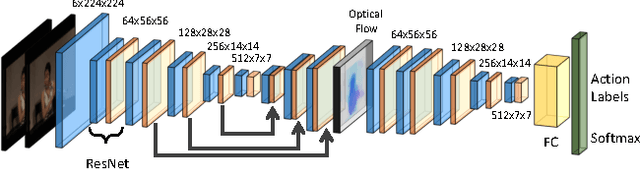
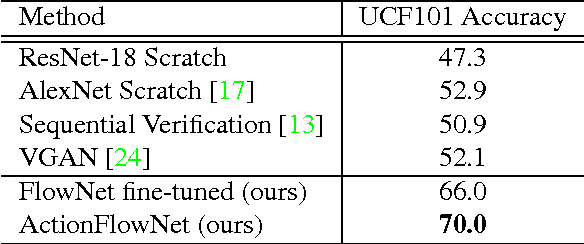
Even with the recent advances in convolutional neural networks (CNN) in various visual recognition tasks, the state-of-the-art action recognition system still relies on hand crafted motion feature such as optical flow to achieve the best performance. We propose a multitask learning model ActionFlowNet to train a single stream network directly from raw pixels to jointly estimate optical flow while recognizing actions with convolutional neural networks, capturing both appearance and motion in a single model. We additionally provide insights to how the quality of the learned optical flow affects the action recognition. Our model significantly improves action recognition accuracy by a large margin 31% compared to state-of-the-art CNN-based action recognition models trained without external large scale data and additional optical flow input. Without pretraining on large external labeled datasets, our model, by well exploiting the motion information, achieves competitive recognition accuracy to the models trained with large labeled datasets such as ImageNet and Sport-1M.
Learning Temporal Regularity in Video Sequences
Apr 15, 2016


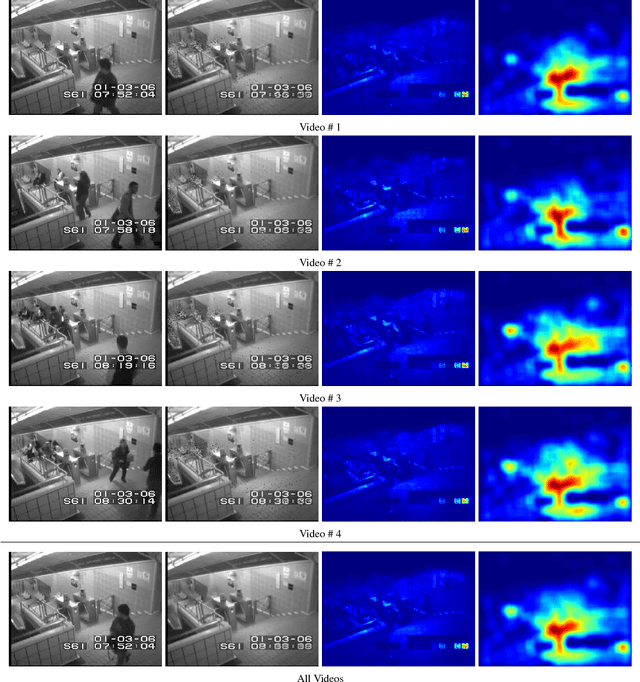
Perceiving meaningful activities in a long video sequence is a challenging problem due to ambiguous definition of 'meaningfulness' as well as clutters in the scene. We approach this problem by learning a generative model for regular motion patterns, termed as regularity, using multiple sources with very limited supervision. Specifically, we propose two methods that are built upon the autoencoders for their ability to work with little to no supervision. We first leverage the conventional handcrafted spatio-temporal local features and learn a fully connected autoencoder on them. Second, we build a fully convolutional feed-forward autoencoder to learn both the local features and the classifiers as an end-to-end learning framework. Our model can capture the regularities from multiple datasets. We evaluate our methods in both qualitative and quantitative ways - showing the learned regularity of videos in various aspects and demonstrating competitive performance on anomaly detection datasets as an application.