 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbourhood Distillation: On the benefits of non end-to-end distillation
Oct 08, 2020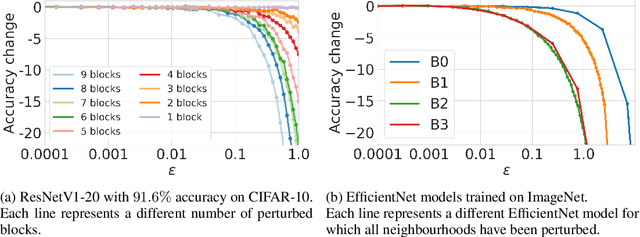
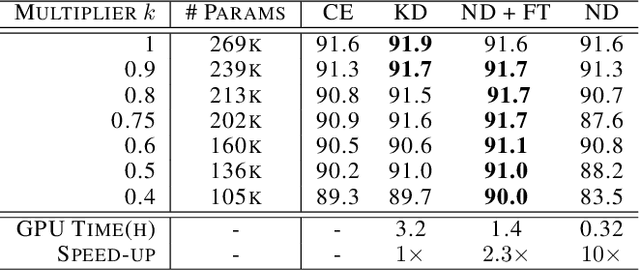
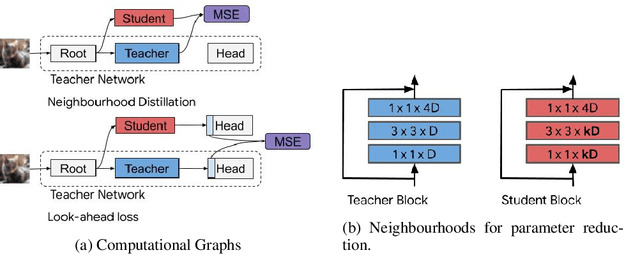
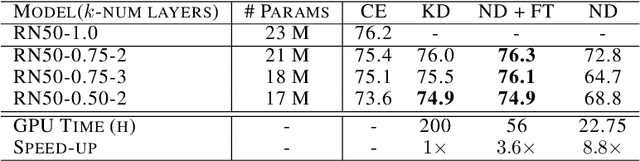
End-to-end training with back propagation is the standard method for training deep neural networks. However, as networks become deeper and bigger, end-to-end training becomes more challenging: highly non-convex models gets stuck easily in local optima, gradients signals are prone to vanish or explode during back-propagation, training requires computational resources and time. In this work, we propose to break away from the end-to-end paradigm in the context of Knowledge Distillation. Instead of distilling a model end-to-end, we propose to split it into smaller sub-networks - also called neighbourhoods - that are then trained independently. We empirically show that distilling networks in a non end-to-end fashion can be beneficial in a diverse range of use cases. First, we show that it speeds up Knowledge Distillation by exploiting parallelism and training on smaller networks. Second, we show that independently distilled neighbourhoods may be efficiently re-used for Neural Architecture Search. Finally, because smaller networks model simpler functions, we show that they are easier to train with synthetic data than their deeper counterparts.
Fine-Grained Stochastic Architecture Search
Jun 17, 2020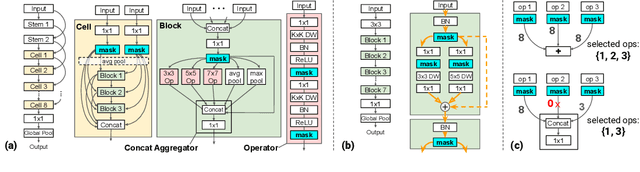
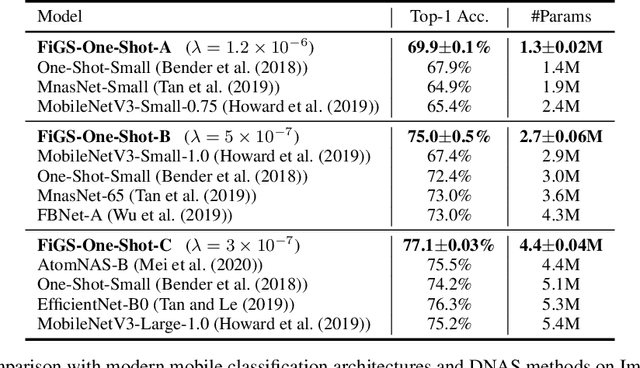
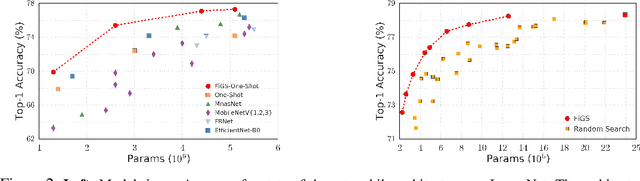

State-of-the-art deep networks are often too large to deploy on mobile devices and embedded systems. Mobile neural architecture search (NAS) methods automate the design of small models but state-of-the-art NAS methods are expensive to run. Differentiable neural architecture search (DNAS) methods reduce the search cost but explore a limited subspace of candidate architectures. In this paper, we introduce Fine-Grained Stochastic Architecture Search (FiGS), a differentiable search method that searches over a much larger set of candidate architectures. FiGS simultaneously selects and modifies operators in the search space by applying a structured sparse regularization penalty based on the Logistic-Sigmoid distribution. We show results across 3 existing search spaces, matching or outperforming the original search algorithms and producing state-of-the-art parameter-efficient models on ImageNet (e.g., 75.4% top-1 with 2.6M params). Using our architectures as backbones for object detection with SSDLite, we achieve significantly higher mAP on COCO (e.g., 25.8 with 3.0M params) than MobileNetV3 and MnasNet.