 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Fine-Grained Stochastic Architecture Search
Jun 17, 2020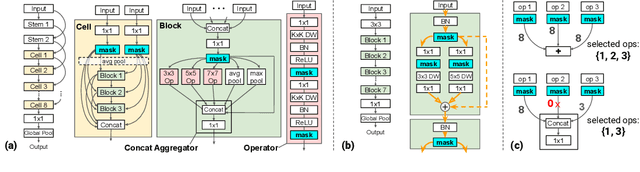
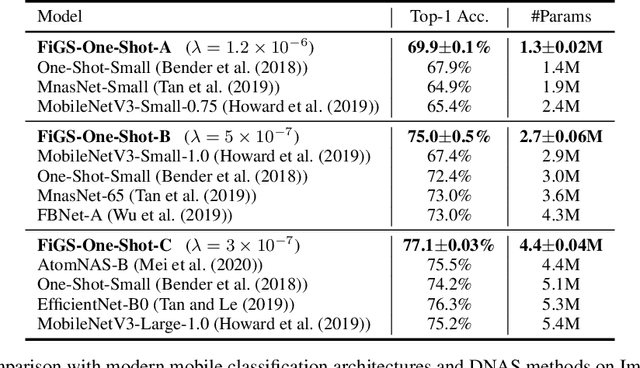
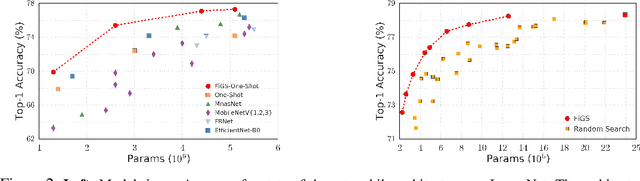

State-of-the-art deep networks are often too large to deploy on mobile devices and embedded systems. Mobile neural architecture search (NAS) methods automate the design of small models but state-of-the-art NAS methods are expensive to run. Differentiable neural architecture search (DNAS) methods reduce the search cost but explore a limited subspace of candidate architectures. In this paper, we introduce Fine-Grained Stochastic Architecture Search (FiGS), a differentiable search method that searches over a much larger set of candidate architectures. FiGS simultaneously selects and modifies operators in the search space by applying a structured sparse regularization penalty based on the Logistic-Sigmoid distribution. We show results across 3 existing search spaces, matching or outperforming the original search algorithms and producing state-of-the-art parameter-efficient models on ImageNet (e.g., 75.4% top-1 with 2.6M params). Using our architectures as backbones for object detection with SSDLite, we achieve significantly higher mAP on COCO (e.g., 25.8 with 3.0M params) than MobileNetV3 and MnasNet.
Deep Tensor Convolution on Multicores
Jun 11, 2017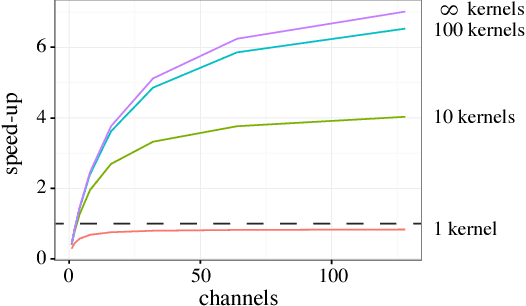
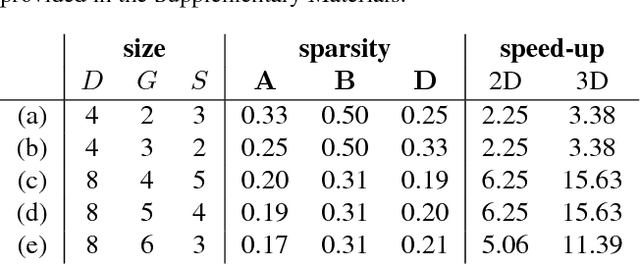
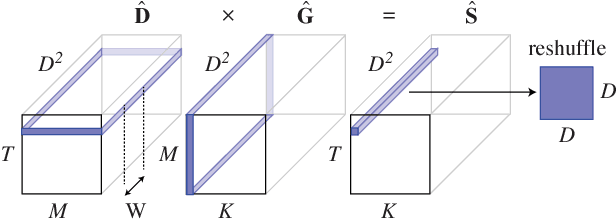
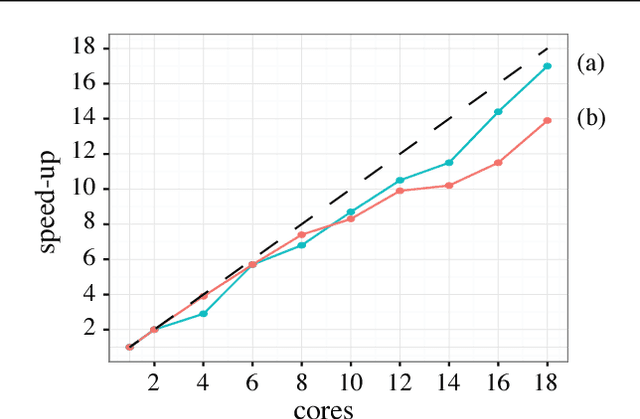
Deep convolutional neural networks (ConvNets) of 3-dimensional kernels allow joint modeling of spatiotemporal features. These networks have improved performance of video and volumetric image analysis, but have been limited in size due to the low memory ceiling of GPU hardware. Existing CPU implementations overcome this constraint but are impractically slow. Here we extend and optimize the faster Winograd-class of convolutional algorithms to the $N$-dimensional case and specifically for CPU hardware. First, we remove the need to manually hand-craft algorithms by exploiting the relaxed constraints and cheap sparse access of CPU memory. Second, we maximize CPU utilization and multicore scalability by transforming data matrices to be cache-aware, integer multiples of AVX vector widths. Treating 2-dimensional ConvNets as a special (and the least beneficial) case of our approach, we demonstrate a 5 to 25-fold improvement in throughput compared to previous state-of-the-art.