 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbourhood Distillation: On the benefits of non end-to-end distillation
Paper and Code
Oct 08, 2020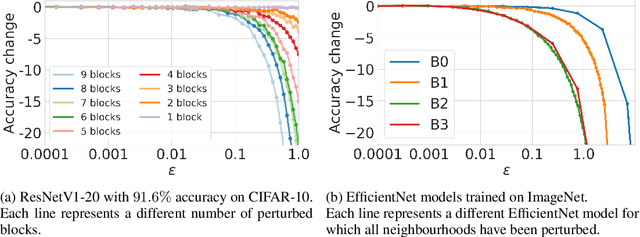
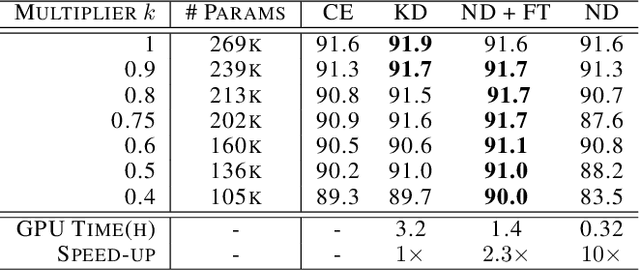
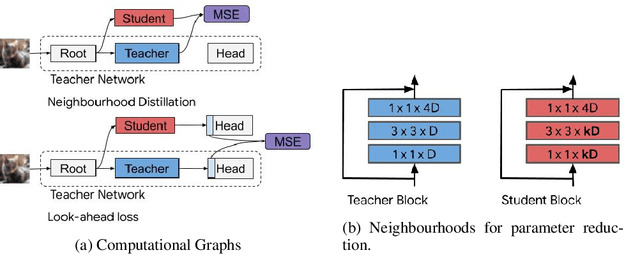
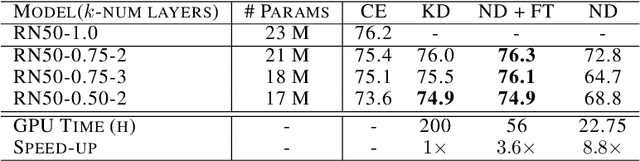
End-to-end training with back propagation is the standard method for training deep neural networks. However, as networks become deeper and bigger, end-to-end training becomes more challenging: highly non-convex models gets stuck easily in local optima, gradients signals are prone to vanish or explode during back-propagation, training requires computational resources and time. In this work, we propose to break away from the end-to-end paradigm in the context of Knowledge Distillation. Instead of distilling a model end-to-end, we propose to split it into smaller sub-networks - also called neighbourhoods - that are then trained independently. We empirically show that distilling networks in a non end-to-end fashion can be beneficial in a diverse range of use cases. First, we show that it speeds up Knowledge Distillation by exploiting parallelism and training on smaller networks. Second, we show that independently distilled neighbourhoods may be efficiently re-used for Neural Architecture Search. Finally, because smaller networks model simpler functions, we show that they are easier to train with synthetic data than their deeper counterparts.