 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning
Paper and Code
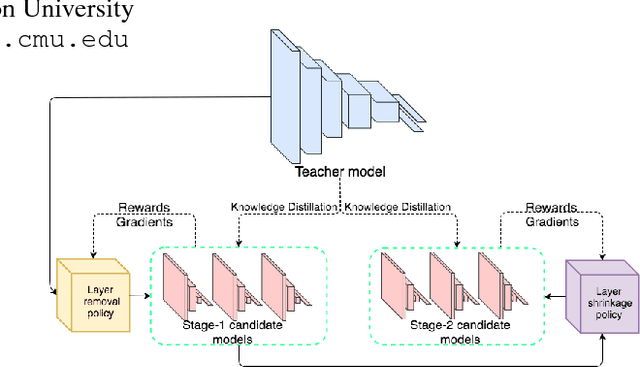
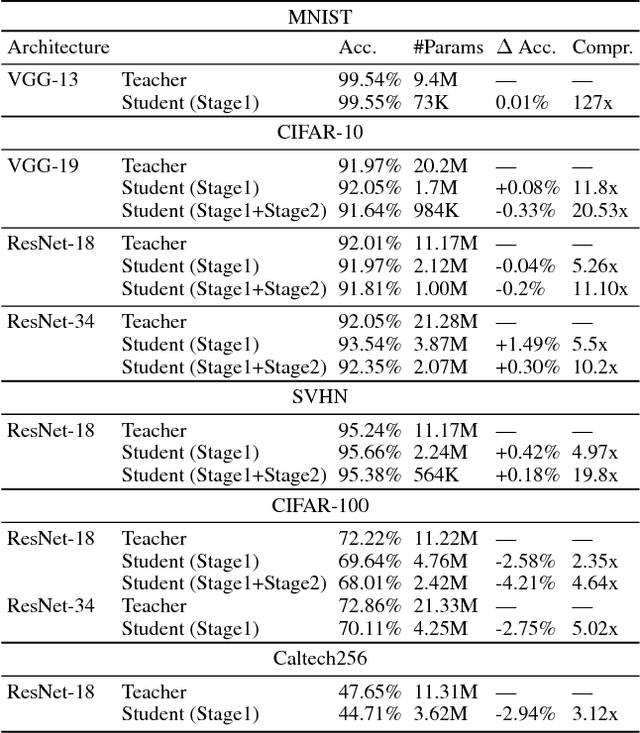
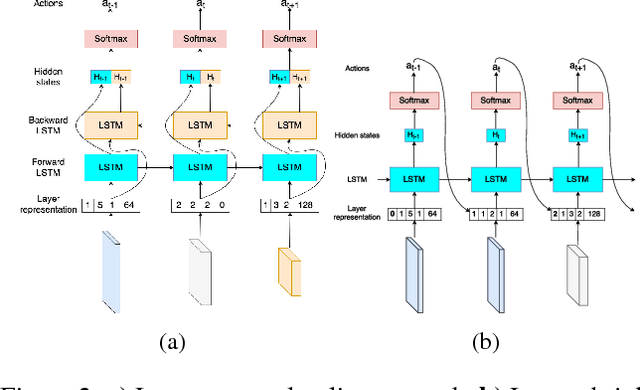
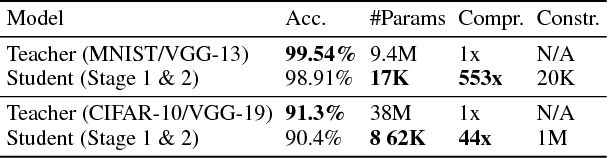
While bigger and deeper neural network architectures continue to advance the state-of-the-art for many computer vision tasks, real-world adoption of these networks is impeded by hardware and speed constraints. Conventional model compression methods attempt to address this problem by modifying the architecture manually or using pre-defined heuristics. Since the space of all reduced architectures is very large, modifying the architecture of a deep neural network in this way is a difficult task. In this paper, we tackle this issue by introducing a principled method for learning reduced network architectures in a data-driven way using reinforcement learning. Our approach takes a larger `teacher' network as input and outputs a compressed `student' network derived from the `teacher' network. In the first stage of our method, a recurrent policy network aggressively removes layers from the large `teacher' model. In the second stage, another recurrent policy network carefully reduces the size of each remaining layer. The resulting network is then evaluated to obtain a reward -- a score based on the accuracy and compression of the network. Our approach uses this reward signal with policy gradients to train the policies to find a locally optimal student network. Our experiments show that we can achieve compression rates of more than 10x for models such as ResNet-34 while maintaining similar performance to the input `teacher' network. We also present a valuable transfer learning result which shows that policies which are pre-trained on smaller `teacher' networks can be used to rapidly speed up training on larger `teacher' networks.