 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effect of Sensor Modalities in Multi-Sensor Detection-Prediction Models
Jan 09, 2021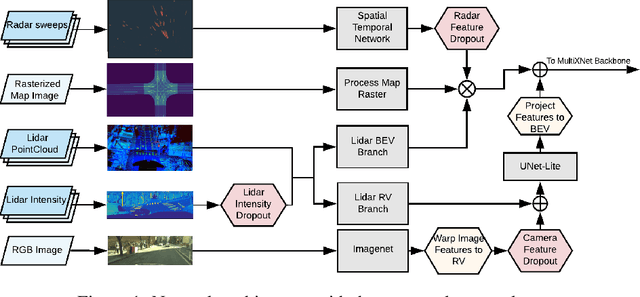
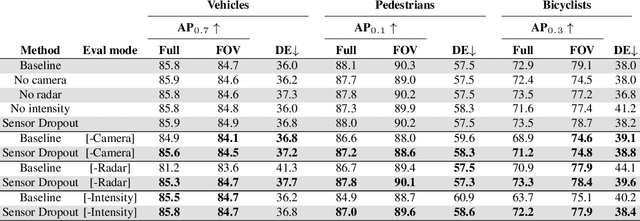
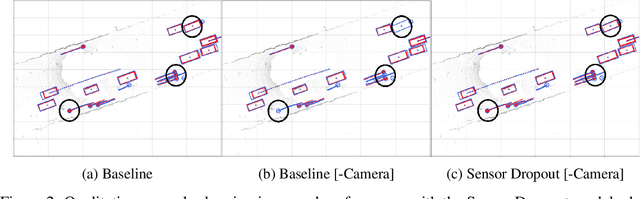
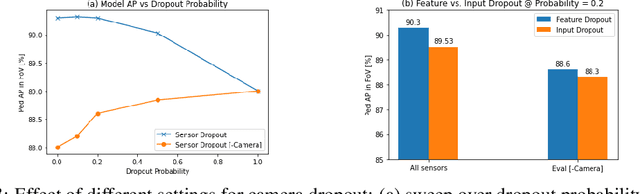
Detection of surrounding objects and their motion prediction are critical components of a self-driving system. Recently proposed models that jointly address these tasks rely on a number of sensors to achieve state-of-the-art performance. However, this increases system complexity and may result in a brittle model that overfits to any single sensor modality while ignoring others, leading to reduced generalization. We focus on this important problem and analyze the contribution of sensor modalities towards the model performance. In addition, we investigate the use of sensor dropout to mitigate the above-mentioned issues, leading to a more robust, better-performing model on real-world driving data.
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020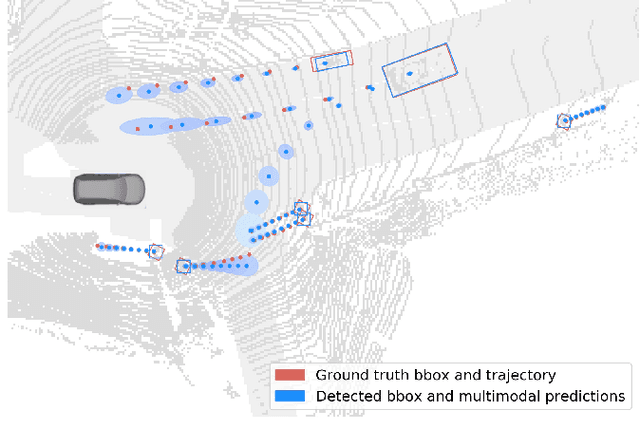
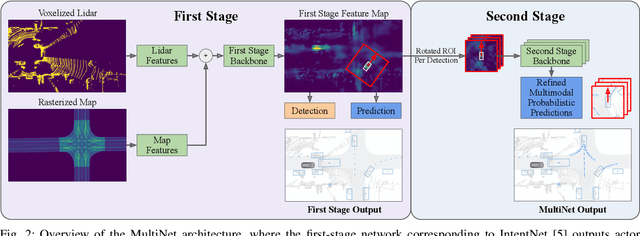
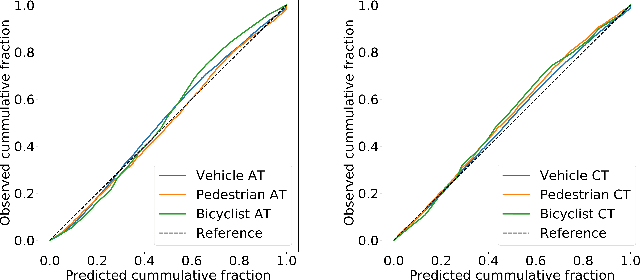
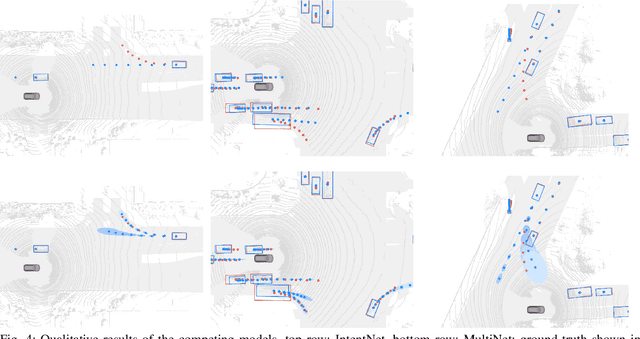
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.
SDVTracker: Real-Time Multi-Sensor Association and Tracking for Self-Driving Vehicles
Mar 09, 2020
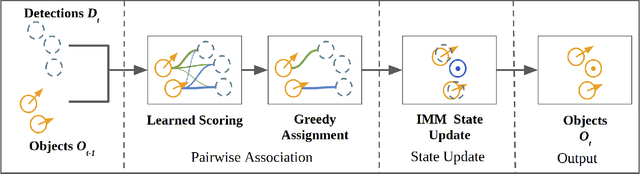
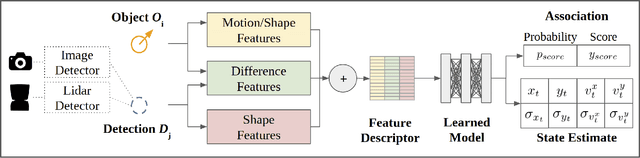
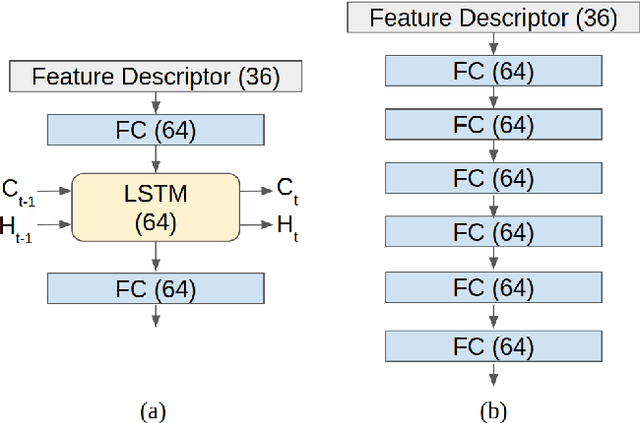
Accurate motion state estimation of Vulnerable Road Users (VRUs), is a critical requirement for autonomous vehicles that navigate in urban environments. Due to their computational efficiency, many traditional autonomy systems perform multi-object tracking using Kalman Filters which frequently rely on hand-engineered association. However, such methods fail to generalize to crowded scenes and multi-sensor modalities, often resulting in poor state estimates which cascade to inaccurate predictions. We present a practical and lightweight tracking system, SDVTracker, that uses a deep learned model for association and state estimation in conjunction with an Interacting Multiple Model (IMM) filter. The proposed tracking method is fast, robust and generalizes across multiple sensor modalities and different VRU classes. In this paper, we detail a model that jointly optimizes both association and state estimation with a novel loss, an algorithm for determining ground-truth supervision, and a training procedure. We show this system significantly outperforms hand-engineered methods on a real-world urban driving dataset while running in less than 2.5 ms on CPU for a scene with 100 actors, making it suitable for self-driving applications where low latency and high accuracy is critical.