 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Discovery of Informative Tweets During the Emerging Disasters
Paper and Code
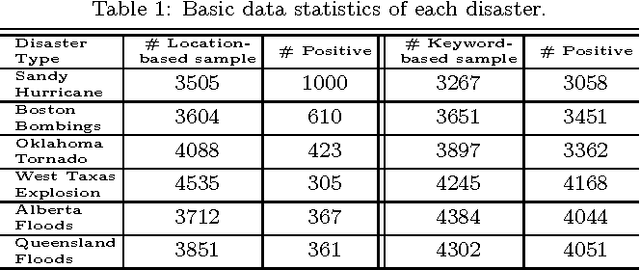
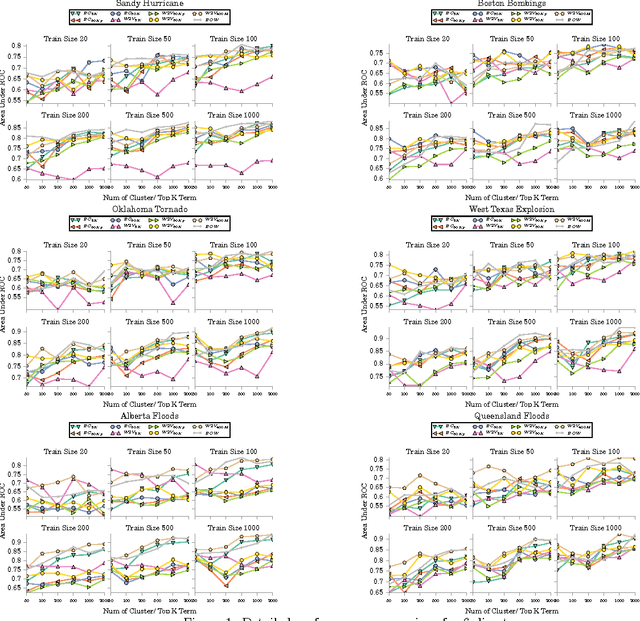
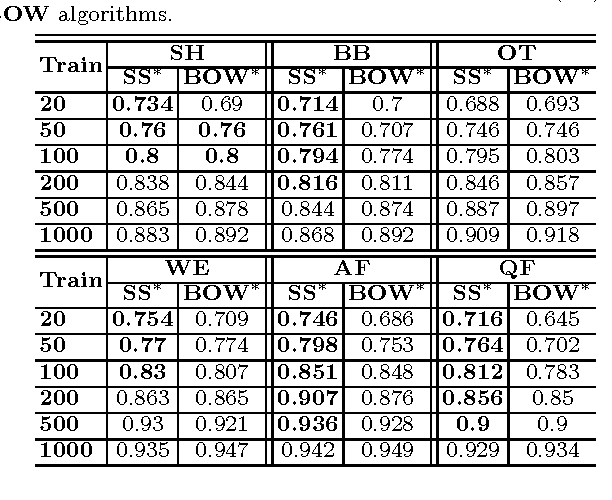
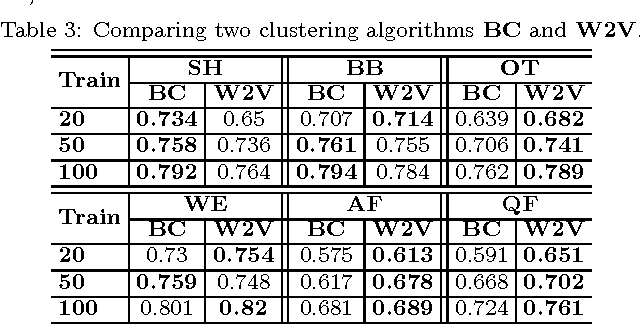
The first objective towards the effective use of microblogging services such as Twitter for situational awareness during the emerging disasters is discovery of the disaster-related postings. Given the wide range of possible disasters, using a pre-selected set of disaster-related keywords for the discovery is suboptimal. An alternative that we focus on in this work is to train a classifier using a small set of labeled postings that are becoming available as a disaster is emerging. Our hypothesis is that utilizing large quantities of historical microblogs could improve the quality of classification, as compared to training a classifier only on the labeled data. We propose to use unlabeled microblogs to cluster words into a limited number of clusters and use the word clusters as features for classification. To evaluate the proposed semi-supervised approach, we used Twitter data from 6 different disasters. Our results indicate that when the number of labeled tweets is 100 or less, the proposed approach is superior to the standard classification based on the bag or words feature representation. Our results also reveal that the choice of the unlabeled corpus, the choice of word clustering algorithm, and the choice of hyperparameters can have a significant impact on the classification accuracy.