 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Contrastive Framework for Low-Resource Cross-Lingual Named Entity Recognition
Paper and Code
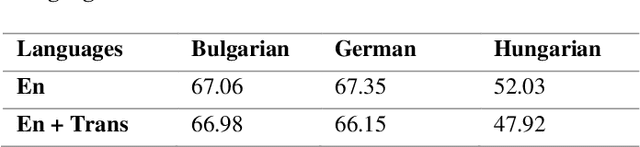
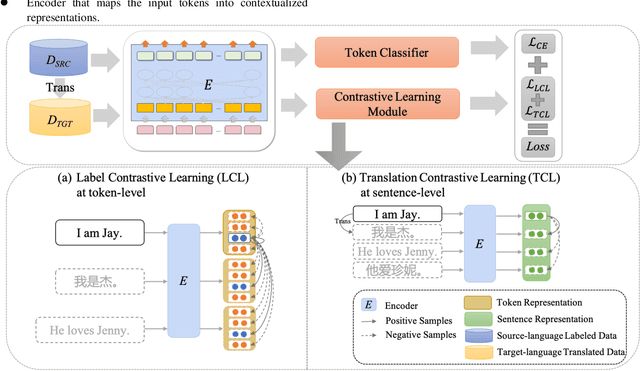
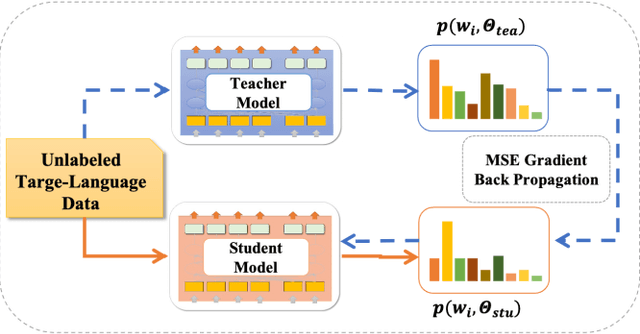
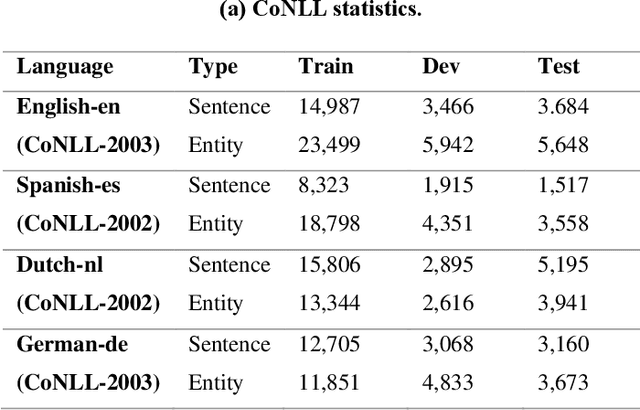
Cross-lingual Named Entity Recognition (NER) has recently become a research hotspot because it can alleviate the data-hungry problem for low-resource languages. However, few researches have focused on the scenario where the source-language labeled data is also limited in some specific domains. A common approach for this scenario is to generate more training data through translation or generation-based data augmentation method. Unfortunately, we find that simply combining source-language data and the corresponding translation cannot fully exploit the translated data and the improvements obtained are somewhat limited. In this paper, we describe our novel dual-contrastive framework ConCNER for cross-lingual NER under the scenario of limited source-language labeled data. Specifically, based on the source-language samples and their translations, we design two contrastive objectives for cross-language NER at different grammatical levels, namely Translation Contrastive Learning (TCL) to close sentence representations between translated sentence pairs and Label Contrastive Learning (LCL) to close token representations within the same labels. Furthermore, we utilize knowledge distillation method where the NER model trained above is used as the teacher to train a student model on unlabeled target-language data to better fit the target language. We conduct extensive experiments on a wide variety of target languages, and the results demonstrate that ConCNER tends to outperform multiple baseline methods. For reproducibility, our code for this paper is available at https://github.com/GKLMIP/ConCNER.