 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaoPLM: Pre-trained Language Models for Lao
Oct 14, 2021

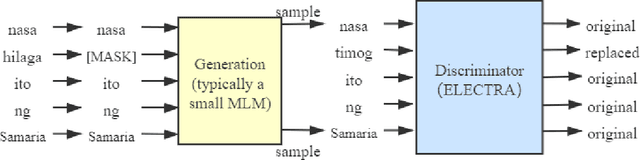

Trained on the large corpus, pre-trained language models (PLMs) can capture different levels of concepts in context and hence generate universal language representations. They can benefit multiple downstream natural language processing (NLP) tasks. Although PTMs have been widely used in most NLP applications, especially for high-resource languages such as English, it is under-represented in Lao NLP research. Previous work on Lao has been hampered by the lack of annotated datasets and the sparsity of language resources. In this work, we construct a text classification dataset to alleviate the resource-scare situation of the Lao language. We additionally present the first transformer-based PTMs for Lao with four versions: BERT-small, BERT-base, ELECTRA-small and ELECTRA-base, and evaluate it over two downstream tasks: part-of-speech tagging and text classification. Experiments demonstrate the effectiveness of our Lao models. We will release our models and datasets to the community, hoping to facilitate the future development of Lao NLP applications.