 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-XABSA: Contrastive Learning for Cross-lingual Aspect-based Sentiment Analysis
Paper and Code
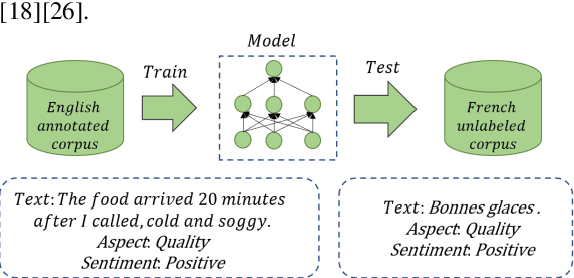
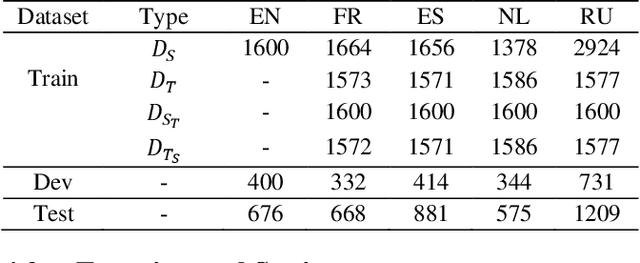
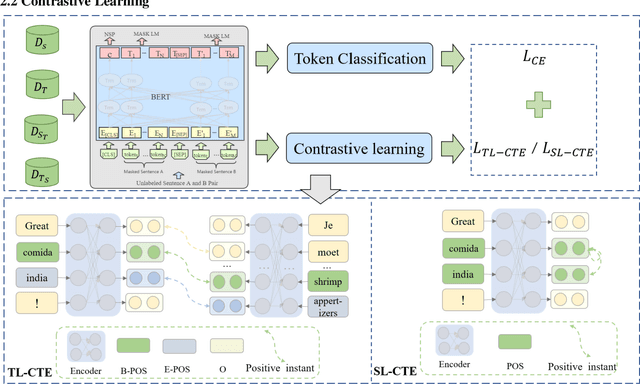
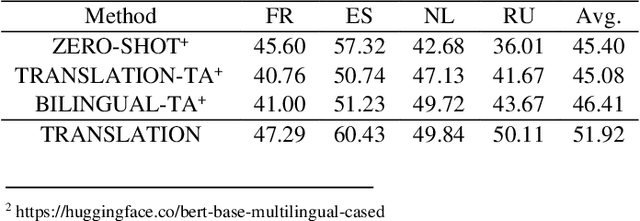
As an extensive research in the field of Natural language processing (NLP), aspect-based sentiment analysis (ABSA) is the task of predicting the sentiment expressed in a text relative to the corresponding aspect. Unfortunately, most languages lack of sufficient annotation resources, thus more and more recent researchers focus on cross-lingual aspect-based sentiment analysis (XABSA). However, most recent researches only concentrate on cross-lingual data alignment instead of model alignment. To this end, we propose a novel framework, CL-XABSA: Contrastive Learning for Cross-lingual Aspect-Based Sentiment Analysis. Specifically, we design two contrastive strategies, token level contrastive learning of token embeddings (TL-CTE) and sentiment level contrastive learning of token embeddings (SL-CTE), to regularize the semantic space of source and target language to be more uniform. Since our framework can receive datasets in multiple languages during training, our framework can be adapted not only for XABSA task, but also for multilingual aspect-based sentiment analysis (MABSA). To further improve the performance of our model, we perform knowledge distillation technology leveraging data from unlabeled target language. In the distillation XABSA task, we further explore the comparative effectiveness of different data (source dataset, translated dataset, and code-switched dataset). The results demonstrate that the proposed method has a certain improvement in the three tasks of XABSA, distillation XABSA and MABSA. For reproducibility, our code for this paper is available at https://github.com/GKLMIP/CL-XABSA.