 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunshan Cup 2020: Overview of the Part-of-Speech Tagging Task for Low-resourced Languages
Apr 06, 2022
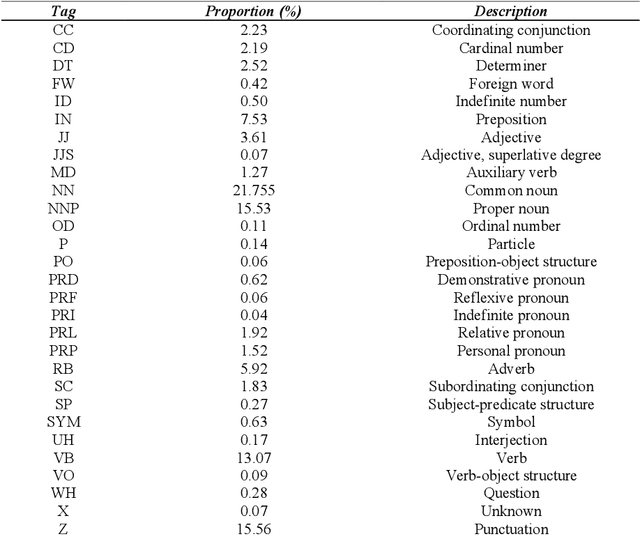
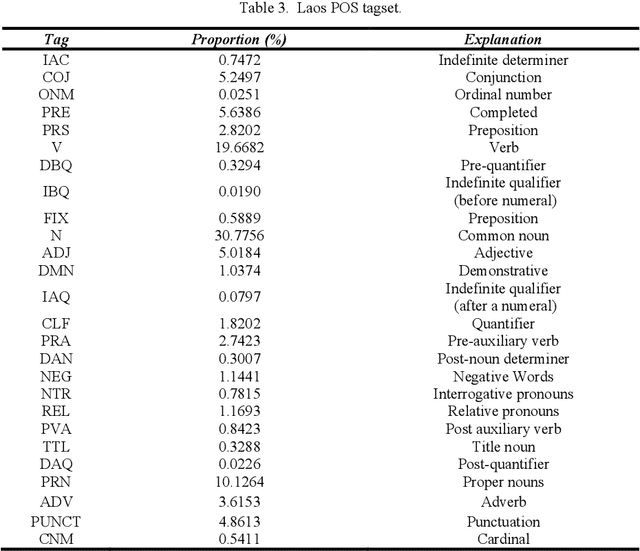
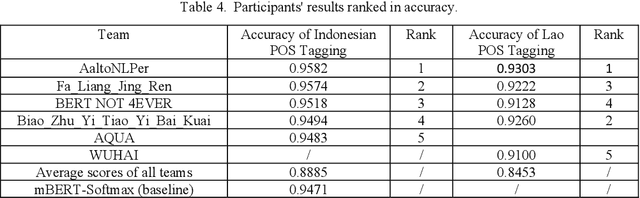
The Yunshan Cup 2020 track focused on creating a framework for evaluating different methods of part-of-speech (POS). There were two tasks for this track: (1) POS tagging for the Indonesian language, and (2) POS tagging for the Lao tagging. The Indonesian dataset is comprised of 10000 sentences from Indonesian news within 29 tags. And the Lao dataset consists of 8000 sentences within 27 tags. 25 teams registered for the task. The methods of participants ranged from feature-based to neural networks using either classical machine learning techniques or ensemble methods. The best performing results achieve an accuracy of 95.82% for Indonesian and 93.03%, showing that neural sequence labeling models significantly outperform classic feature-based methods and rule-based methods.