 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems
Paper and Code
Feb 17, 2021
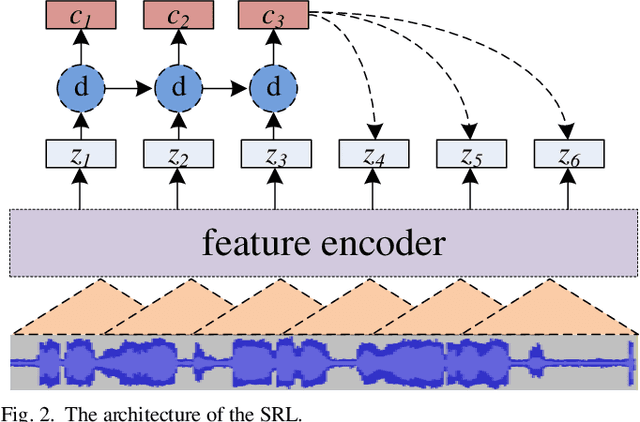
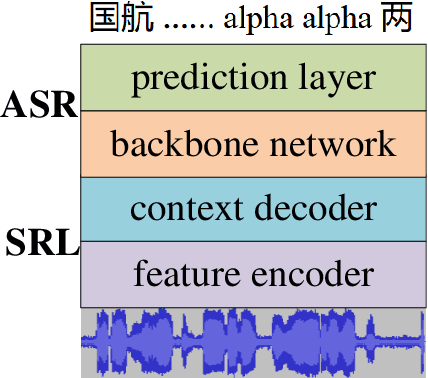

In this paper, a multilingual end-to-end framework, called as ATCSpeechNet, is proposed to tackle the issue of translating communication speech into human-readable text in air traffic control (ATC) systems. In the proposed framework, we focus on integrating the multilingual automatic speech recognition (ASR) into one model, in which an end-to-end paradigm is developed to convert speech waveform into text directly, without any feature engineering or lexicon. In order to make up for the deficiency of the handcrafted feature engineering caused by ATC challenges, a speech representation learning (SRL) network is proposed to capture robust and discriminative speech representations from the raw wave. The self-supervised training strategy is adopted to optimize the SRL network from unlabeled data, and further to predict the speech features, i.e., wave-to-feature. An end-to-end architecture is improved to complete the ASR task, in which a grapheme-based modeling unit is applied to address the multilingual ASR issue. Facing the problem of small transcribed samples in the ATC domain, an unsupervised approach with mask prediction is applied to pre-train the backbone network of the ASR model on unlabeled data by a feature-to-feature process. Finally, by integrating the SRL with ASR, an end-to-end multilingual ASR framework is formulated in a supervised manner, which is able to translate the raw wave into text in one model, i.e., wave-to-text. Experimental results on the ATCSpeech corpus demonstrate that the proposed approach achieves a high performance with a very small labeled corpus and less resource consumption, only 4.20% label error rate on the 58-hour transcribed corpus. Compared to the baseline model, the proposed approach obtains over 100% relative performance improvement which can be further enhanced with the increasing of the size of the transcribed samples.