 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKMMLU: Measuring Massive Multitask Language Understanding in Korean
Paper and Code
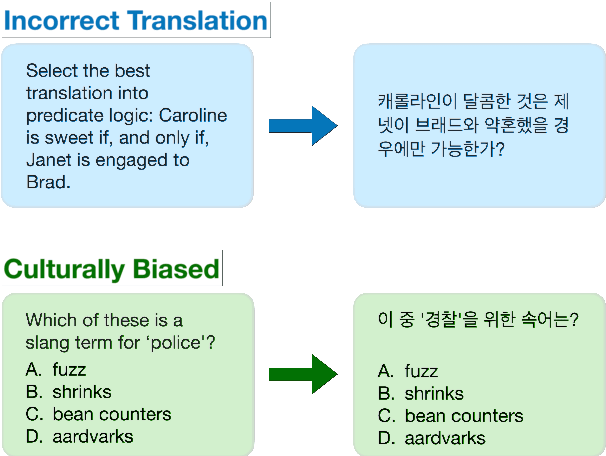



We propose KMMLU, a new Korean benchmark with 35,030 expert-level multiple-choice questions across 45 subjects ranging from humanities to STEM. Unlike previous Korean benchmarks that are translated from existing English benchmarks, KMMLU is collected from original Korean exams, capturing linguistic and cultural aspects of the Korean language. We test 26 publically available and proprietary LLMs, identifying significant room for improvement. The best publicly available model achieves 50.54% on KMMLU, far below the average human performance of 62.6%. This model was primarily trained for English and Chinese, not Korean. Current LLMs tailored to Korean, such as Polyglot-Ko, perform far worse. Surprisingly, even the most capable proprietary LLMs, e.g., GPT-4 and HyperCLOVA X, achieve 59.95% and 53.40%, respectively. This suggests that further work is needed to improve Korean LLMs, and KMMLU offers the right tool to track this progress. We make our dataset publicly available on the Hugging Face Hub and integrate the benchmark into EleutherAI's Language Model Evaluation Harness.