Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Ascent Post-training Enhances Language Model Generalization
Paper and Code
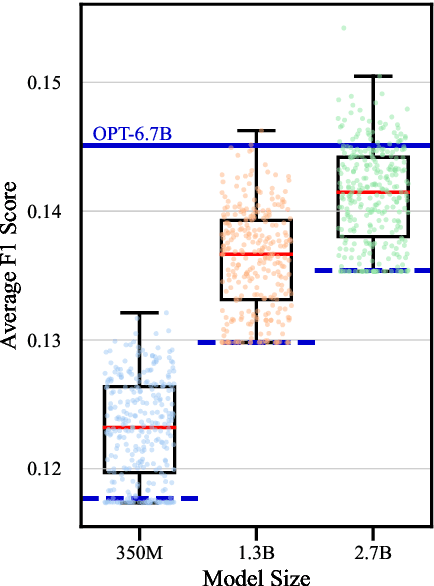
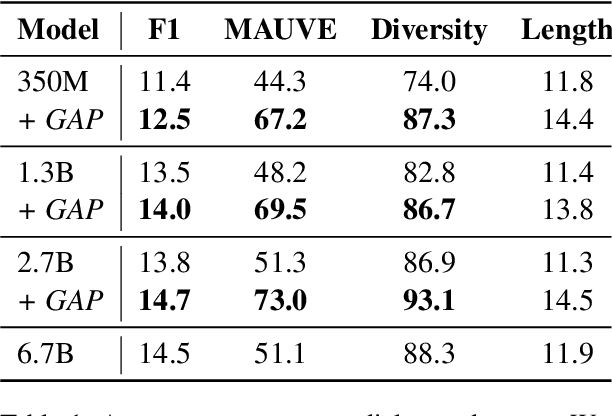
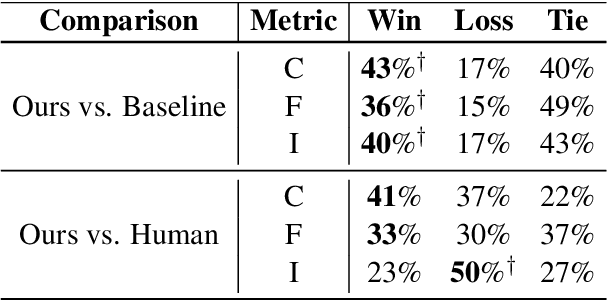
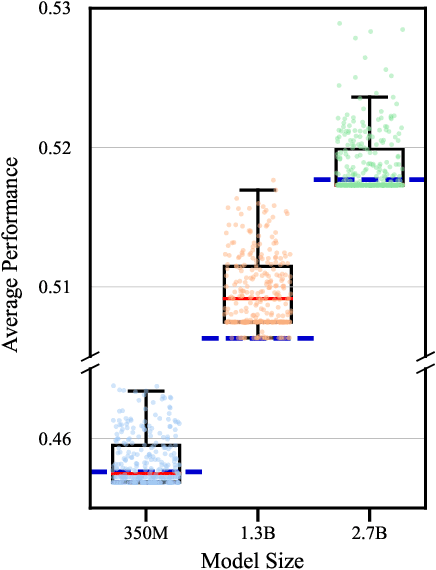
In this work, we empirically show that updating pretrained LMs (350M, 1.3B, 2.7B) with just a few steps of Gradient Ascent Post-training (GAP) on random, unlabeled text corpora enhances its zero-shot generalization capabilities across diverse NLP tasks. Specifically, we show that GAP can allow LMs to become comparable to 2-3x times larger LMs across 12 different NLP tasks. We also show that applying GAP on out-of-distribution corpora leads to the most reliable performance improvements. Our findings indicate that GAP can be a promising method for improving the generalization capability of LMs without any task-specific fine-tuning.
* ACL 2023 Main Conference (Short Paper)
View paper on