 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg2Box: 3D Object Detection by Point-Wise Semantics Supervision
Paper and Code
Mar 21, 2025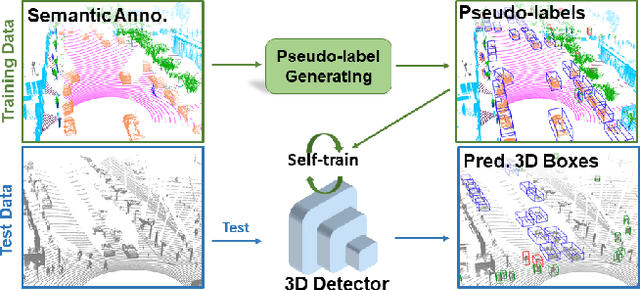
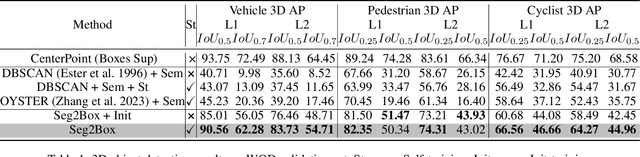
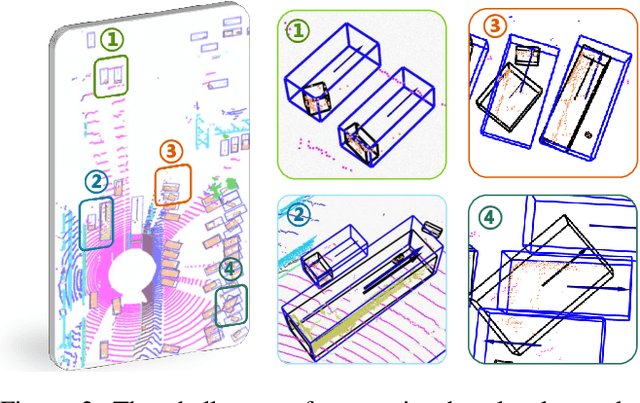
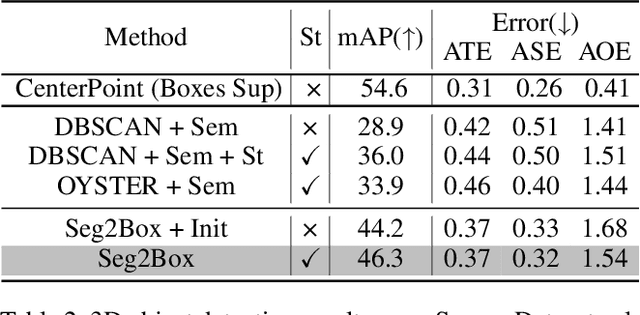
LiDAR-based 3D object detection and semantic segmentation are critical tasks in 3D scene understanding. Traditional detection and segmentation methods supervise their models through bounding box labels and semantic mask labels. However, these two independent labels inherently contain significant redundancy. This paper aims to eliminate the redundancy by supervising 3D object detection using only semantic labels. However, the challenge arises due to the incomplete geometry structure and boundary ambiguity of point-cloud instances, leading to inaccurate pseudo labels and poor detection results. To address these challenges, we propose a novel method, named Seg2Box. We first introduce a Multi-Frame Multi-Scale Clustering (MFMS-C) module, which leverages the spatio-temporal consistency of point clouds to generate accurate box-level pseudo-labels. Additionally, the Semantic?Guiding Iterative-Mining Self-Training (SGIM-ST) module is proposed to enhance the performance by progressively refining the pseudo-labels and mining the instances without generating pseudo-labels. Experiments on the Waymo Open Dataset and nuScenes Dataset show that our method significantly outperforms other competitive methods by 23.7\% and 10.3\% in mAP, respectively. The results demonstrate the great label-efficient potential and advancement of our method.