 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Relevance Based Sensor Selection for Edge-AI Empowered Sensing Systems
Mar 17, 2025The sixth-generation (6G) mobile network is envisioned to incorporate sensing and edge artificial intelligence (AI) as two key functions. Their natural convergence leads to the emergence of Integrated Sensing and Edge AI (ISEA), a novel paradigm enabling real-time acquisition and understanding of sensory information at the network edge. However, ISEA faces a communication bottleneck due to the large number of sensors and the high dimensionality of sensory features. Traditional approaches to communication-efficient ISEA lack awareness of semantic relevance, i.e., the level of relevance between sensor observations and the downstream task. To fill this gap, this paper presents a novel framework for semantic-relevance-aware sensor selection to achieve optimal end-to-end (E2E) task performance under heterogeneous sensor relevance and channel states. E2E sensing accuracy analysis is provided to characterize the sensing task performance in terms of selected sensors' relevance scores and channel states. Building on the results, the sensor-selection problem for accuracy maximization is formulated as an integer program and solved through a tight approximation of the objective. The optimal solution exhibits a priority-based structure, which ranks sensors based on a priority indicator combining relevance scores and channel states and selects top-ranked sensors. Low-complexity algorithms are then developed to determine the optimal numbers of selected sensors and features. Experimental results on both synthetic and real datasets show substantial accuracy gain achieved by the proposed selection scheme compared to existing benchmarks.
Integrated Sensing and Edge AI: Realizing Intelligent Perception in 6G
Jan 12, 2025Sensing and edge artificial intelligence (AI) are envisioned as two essential and interconnected functions in sixth-generation (6G) mobile networks. On the one hand, sensing-empowered applications rely on powerful AI models to extract features and understand semantics from ubiquitous wireless sensors. On the other hand, the massive amount of sensory data serves as the fuel to continuously refine edge AI models. This deep integration of sensing and edge AI has given rise to a new task-oriented paradigm known as integrated sensing and edge AI (ISEA), which features a holistic design approach to communication, AI computation, and sensing for optimal sensing-task performance. In this article, we present a comprehensive survey for ISEA. We first provide technical preliminaries for sensing, edge AI, and new communication paradigms in ISEA. Then, we study several use cases of ISEA to demonstrate its practical relevance and introduce current standardization and industrial progress. Next, the design principles, metrics, tradeoffs, and architectures of ISEA are established, followed by a thorough overview of ISEA techniques, including digital air interface, over-the-air computation, and advanced signal processing. Its interplay with various 6G advancements, e.g., new physical-layer and networking techniques, are presented. Finally, we present future research opportunities in ISEA, including the integration of foundation models, convergence of ISEA and integrated sensing and communications (ISAC), and ultra-low-latency ISEA.
Over-the-Air Fusion of Sparse Spatial Features for Integrated Sensing and Edge AI over Broadband Channels
Apr 27, 2024The 6G mobile networks are differentiated from 5G by two new usage scenarios - distributed sensing and edge AI. Their natural integration, termed integrated sensing and edge AI (ISEA), promised to create a platform for enabling environment perception to make intelligent decisions and take real-time actions. A basic operation in ISEA is for a fusion center to acquire and fuse features of spatial sensing data distributed at many agents. To overcome its communication bottleneck due to multiple access by numerous agents over hostile wireless channels, we propose a novel framework, called Spatial Over-the-Air Fusion (Spatial AirFusion), which exploits radio waveform superposition to aggregate spatially sparse features over the air. The technology is more sophisticated than conventional Over-the-Air Computing (AirComp) as it supports simultaneous aggregation over multiple voxels, which partition the 3D sensing region, and across multiple subcarriers. Its efficiency and robustness are derived from exploitation of both spatial feature sparsity and multiuser channel diversity to intelligently pair voxel-level aggregation tasks and subcarriers to maximize the minimum receive SNR among voxels under instantaneous power constraints. To optimally solve the mixed-integer Voxel-Carrier Pairing and Power Allocation (VoCa-PPA) problem, the proposed approach hinges on two useful results: (1) deriving the optimal power allocation as a closed-form function of voxel-carrier pairing and (2) discovering a useful property of VoCa-PPA that dramatically reduces the solution-space dimensionality. Both a low-complexity greedy algorithm and an optimal tree-search based approach are designed for VoCa-PPA. Extensive simulations using real datasets show that Spatial AirFusion achieves significant error reduction and accuracy improvement compared with conventional AirComp without awareness of spatial sparsity.
An Empirical Study of Attention Networks for Semantic Segmentation
Sep 19, 2023Semantic segmentation is a vital problem in computer vision. Recently, a common solution to semantic segmentation is the end-to-end convolution neural network, which is much more accurate than traditional methods.Recently, the decoders based on attention achieve state-of-the-art (SOTA) performance on various datasets. But these networks always are compared with the mIoU of previous SOTA networks to prove their superiority and ignore their characteristics without considering the computation complexity and precision in various categories, which is essential for engineering applications. Besides, the methods to analyze the FLOPs and memory are not consistent between different networks, which makes the comparison hard to be utilized. What's more, various methods utilize attention in semantic segmentation, but the conclusion of these methods is lacking. This paper first conducts experiments to analyze their computation complexity and compare their performance. Then it summarizes suitable scenes for these networks and concludes key points that should be concerned when constructing an attention network. Last it points out some future directions of the attention network.
Over-the-Air Multi-View Pooling for Distributed Sensing
Feb 20, 2023Sensing is envisioned as a key network function of the 6G mobile networks. Artificial intelligence (AI)-empowered sensing fuses features of multiple sensing views from devices distributed in edge networks for the edge server to perform accurate inference. This process, known as multi-view pooling, creates a communication bottleneck due to multi-access by many devices. To alleviate this issue, we propose a task-oriented simultaneous access scheme for distributed sensing called Over-the-Air Pooling (AirPooling). The existing Over-the-Air Computing (AirComp) technique can be directly applied to enable Average-AirPooling by exploiting the waveform superposition property of a multi-access channel. However, despite being most popular in practice, the over-the-air maximization, called Max-AirPooling, is not AirComp realizable as AirComp addresses a limited subset of functions. We tackle the challenge by proposing the novel generalized AirPooling framework that can be configured to support both Max- and Average-AirPooling by controlling a configuration parameter. The former is realized by adding to AirComp the designed pre-processing at devices and post-processing at the server. To characterize the end-to-end sensing performance, the theory of classification margin is applied to relate the classification accuracy and the AirPooling error. Furthermore, the analysis reveals an inherent tradeoff of Max-AirPooling between the accuracy of the pooling-function approximation and the effectiveness of noise suppression. Using the tradeoff, we optimize the configuration parameter of Max-AirPooling, yielding a sub-optimal closed-form method of adaptive parametric control. Experimental results obtained on real-world datasets show that AirPooling provides sensing accuracies close to those achievable by the traditional digital air interface but dramatically reduces the communication latency.
Semantic Data Sourcing for 6G Edge Intelligence
Jan 01, 2023



As a new function of 6G networks, edge intelligence refers to the ubiquitous deployment of machine learning and artificial intelligence (AI) algorithms at the network edge to empower many emerging applications ranging from sensing to auto-pilot. To support relevant use cases, including sensing, edge learning, and edge inference, all require transmission of high-dimensional data or AI models over the air. To overcome the bottleneck, we propose a novel framework of SEMantic DAta Sourcing (SEMDAS) for locating semantically matched data sources to efficiently enable edge-intelligence operations. The comprehensive framework comprises new architecture, protocol, semantic matching techniques, and design principles for task-oriented wireless techniques. As the key component of SEMDAS, we discuss a set of machine learning based semantic matching techniques targeting different edge-intelligence use cases. Moreover, for designing task-oriented wireless techniques, we discuss different tradeoffs in SEMDAS systems, propose the new concept of joint semantics-and-channel matching, and point to a number of research opportunities. The SEMDAS framework not only overcomes the said communication bottleneck but also addresses other networking issues including long-distance transmission, sparse connectivity, high-speed mobility, link disruptions, and security. In addition, experimental results using a real dataset are presented to demonstrate the performance gain of SEMDAS.
In-situ Model Downloading to Realize Versatile Edge AI in 6G Mobile Networks
Oct 07, 2022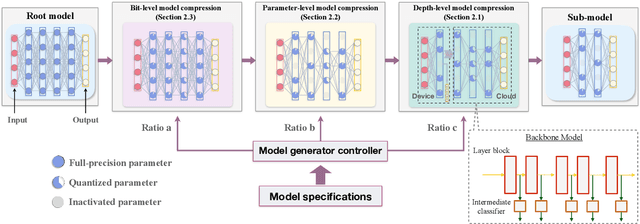

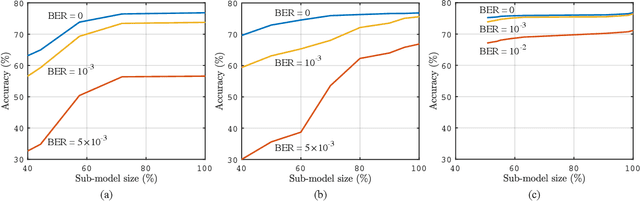
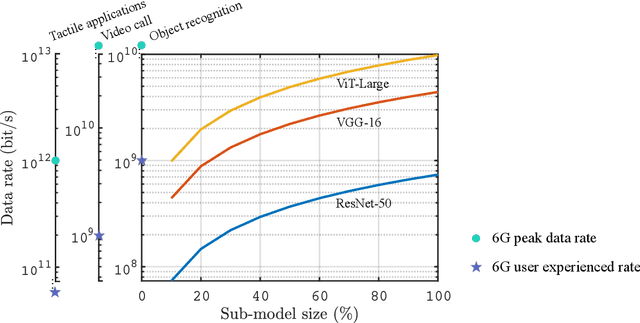
The sixth-generation (6G) mobile networks are expected to feature the ubiquitous deployment of machine learning and AI algorithms at the network edge. With rapid advancements in edge AI, the time has come to realize intelligence downloading onto edge devices (e.g., smartphones and sensors). To materialize this version, we propose a novel technology in this article, called in-situ model downloading, that aims to achieve transparent and real-time replacement of on-device AI models by downloading from an AI library in the network. Its distinctive feature is the adaptation of downloading to time-varying situations (e.g., application, location, and time), devices' heterogeneous storage-and-computing capacities, and channel states. A key component of the presented framework is a set of techniques that dynamically compress a downloaded model at the depth-level, parameter-level, or bit-level to support adaptive model downloading. We further propose a virtualized 6G network architecture customized for deploying in-situ model downloading with the key feature of a three-tier (edge, local, and central) AI library. Furthermore, experiments are conducted to quantify 6G connectivity requirements and research opportunities pertaining to the proposed technology are discussed.
Resource Allocation for Multiuser Edge Inference with Batching and Early Exiting (Extended Version)
Apr 11, 2022


The deployment of inference services at the network edge, called edge inference, offloads computation-intensive inference tasks from mobile devices to edge servers, thereby enhancing the former's capabilities and battery lives. In a multiuser system, the joint allocation of communication-and-computation ($\text{C}^\text{2}$) resources (i.e., scheduling and bandwidth allocation) is made challenging by adopting efficient inference techniques, batching and early exiting, and further complicated by the heterogeneity in users' requirements on accuracy and latency. Batching groups multiple tasks into one batch for parallel processing to reduce time-consuming memory access and thereby boosts the throughput (i.e., completed task per second). On the other hand, early exiting allows a task to exit from a deep-neural network without traversing the whole network to support a tradeoff between accuracy and latency. In this work, we study optimal $\text{C}^\text{2}$ resource allocation with batching and early exiting, which is an NP-complete integer program. A set of efficient algorithms are designed under the criterion of maximum throughput by tackling the challenge. Experimental results demonstrate that both optimal and sub-optimal $\text{C}^\text{2}$ resource allocation algorithms can leverage integrated batching and early exiting to achieve 200% throughput gain over conventional schemes.
Deep Unsupervised Learning for Joint Antenna Selection and Hybrid Beamforming
Jun 06, 2021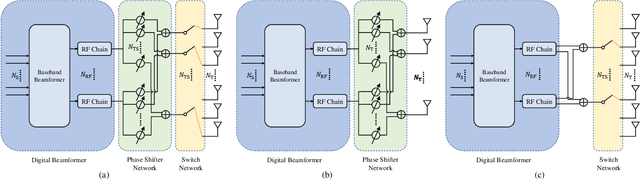
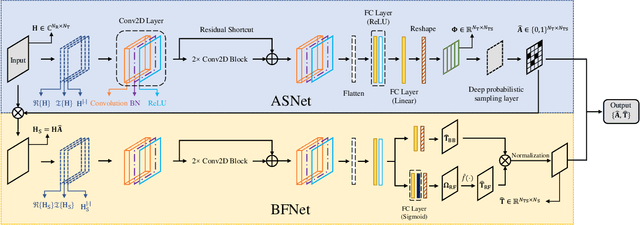
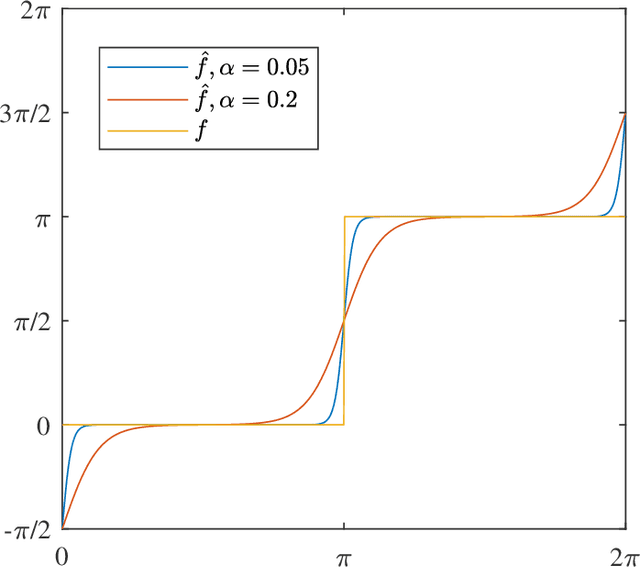
In this paper, we consider a massive multiple-input-multiple-output (MIMO) downlink system that improves the hardware efficiency by dynamically selecting the antenna subarray and utilizing 1-bit phase shifters for hybrid beamforming. To maximize the spectral efficiency, we propose a novel deep unsupervised learning-based approach that avoids the computationally prohibitive process of acquiring training labels. The proposed design has its input as the channel matrix and consists of two convolutional neural networks (CNNs). To enable unsupervised training, the problem constraints are embedded in the neural networks: the first CNN adopts deep probabilistic sampling, while the second CNN features a quantization layer designed for 1-bit phase shifters. The two networks can be trained jointly without labels by sharing an unsupervised loss function. We next propose a phased training approach to promote the convergence of the proposed networks. Simulation results demonstrate the advantage of the proposed approach over conventional optimization-based algorithms in terms of both achieved rate and computational complexity.