 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrictly-ID-Preserved and Controllable Accessory Advertising Image Generation
Apr 07, 2024



Customized generative text-to-image models have the ability to produce images that closely resemble a given subject. However, in the context of generating advertising images for e-commerce scenarios, it is crucial that the generated subject's identity aligns perfectly with the product being advertised. In order to address the need for strictly-ID preserved advertising image generation, we have developed a Control-Net based customized image generation pipeline and have taken earring model advertising as an example. Our approach facilitates a seamless interaction between the earrings and the model's face, while ensuring that the identity of the earrings remains intact. Furthermore, to achieve a diverse and controllable display, we have proposed a multi-branch cross-attention architecture, which allows for control over the scale, pose, and appearance of the model, going beyond the limitations of text prompts. Our method manages to achieve fine-grained control of the generated model's face, resulting in controllable and captivating advertising effects.
DEANet: Decomposition Enhancement and Adjustment Network for Low-Light Image Enhancement
Sep 14, 2022
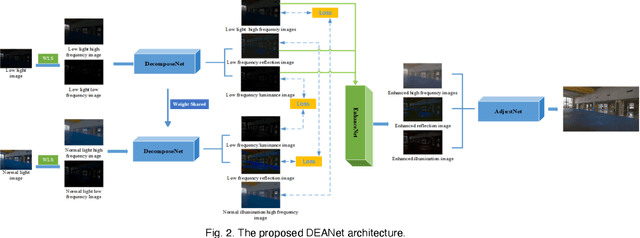
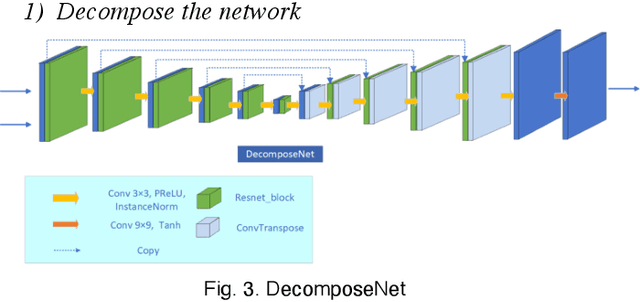
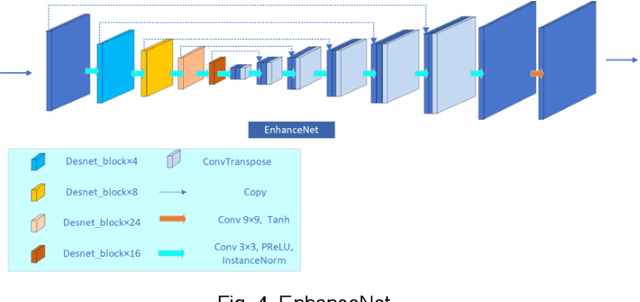
Images obtained under low-light conditions will seriously affect the quality of the images. Solving the problem of poor low-light image quality can effectively improve the visual quality of images and better improve the usability of computer vision. In addition, it has very important applications in many fields. This paper proposes a DEANet based on Retinex for low-light image enhancement. It combines the frequency information and content information of the image into three sub-networks: decomposition network, enhancement network and adjustment network. These three sub-networks are respectively used for decomposition, denoising, contrast enhancement and detail preservation, adjustment, and image generation. Our model has good robust results for all low-light images. The model is trained on the public data set LOL, and the experimental results show that our method is better than the existing state-of-the-art methods in terms of vision and quality.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022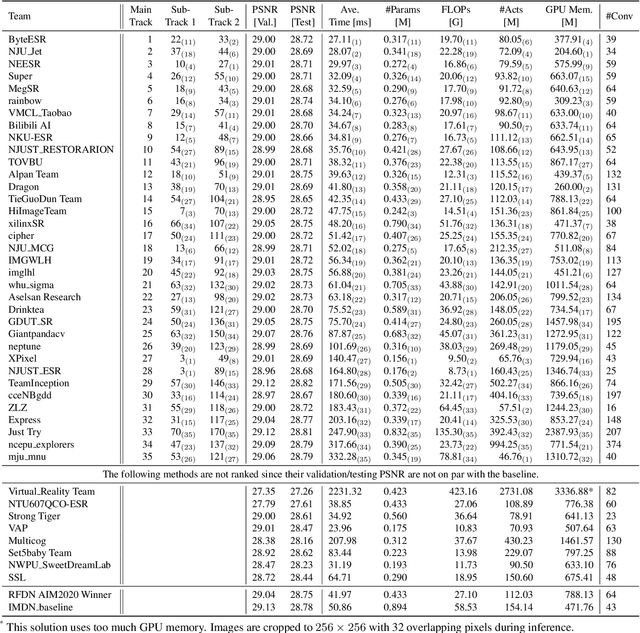
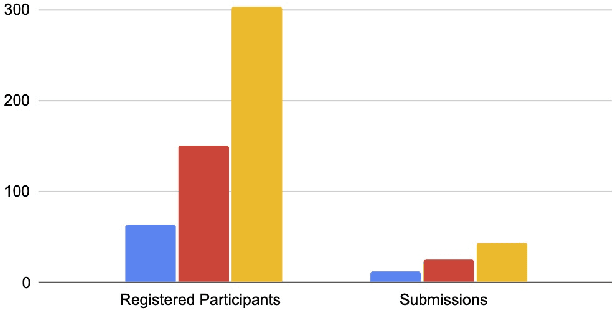
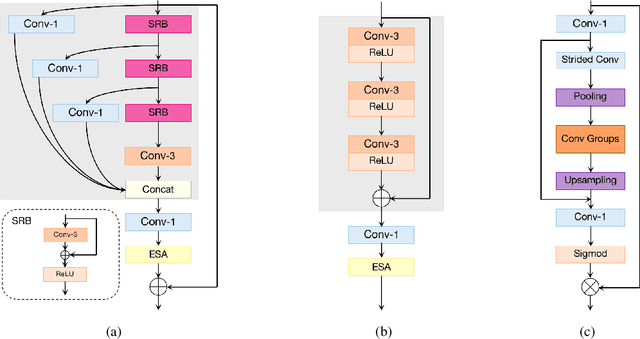
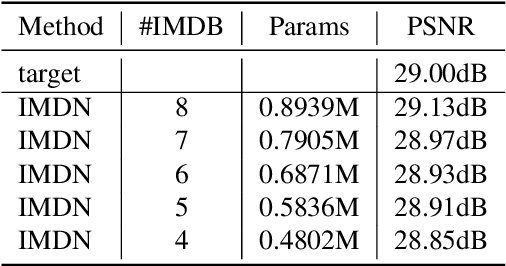
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Deep Unsupervised Learning for Joint Antenna Selection and Hybrid Beamforming
Jun 06, 2021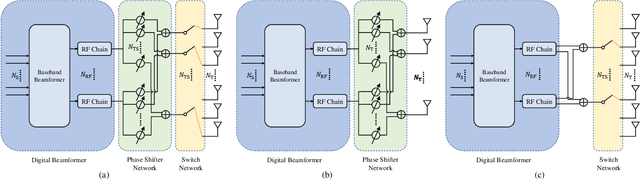
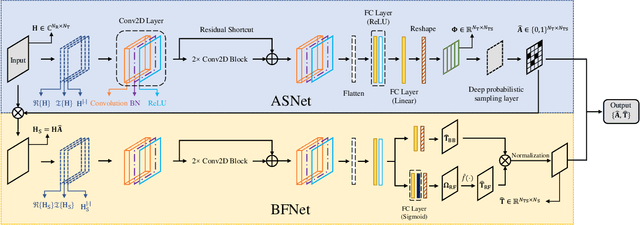
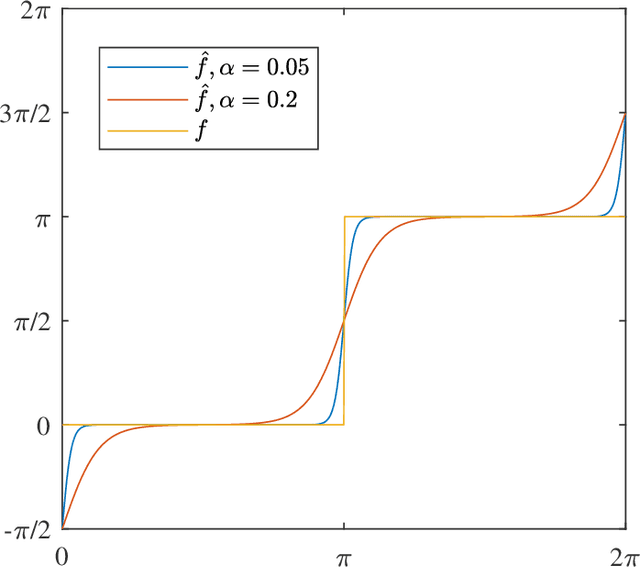
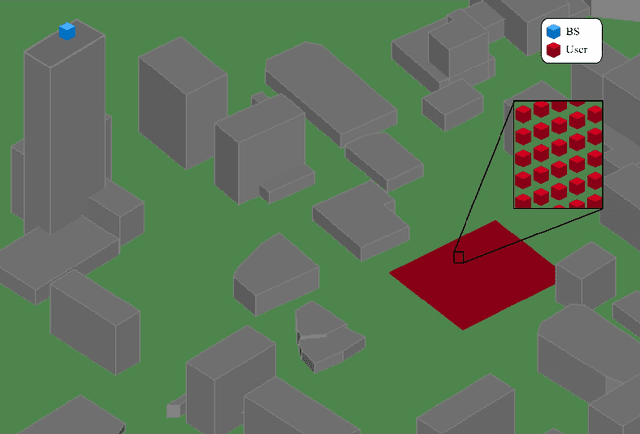
In this paper, we consider a massive multiple-input-multiple-output (MIMO) downlink system that improves the hardware efficiency by dynamically selecting the antenna subarray and utilizing 1-bit phase shifters for hybrid beamforming. To maximize the spectral efficiency, we propose a novel deep unsupervised learning-based approach that avoids the computationally prohibitive process of acquiring training labels. The proposed design has its input as the channel matrix and consists of two convolutional neural networks (CNNs). To enable unsupervised training, the problem constraints are embedded in the neural networks: the first CNN adopts deep probabilistic sampling, while the second CNN features a quantization layer designed for 1-bit phase shifters. The two networks can be trained jointly without labels by sharing an unsupervised loss function. We next propose a phased training approach to promote the convergence of the proposed networks. Simulation results demonstrate the advantage of the proposed approach over conventional optimization-based algorithms in terms of both achieved rate and computational complexity.
Unsupervised segmentation via semantic-apparent feature fusion
May 21, 2020Foreground segmentation is an essential task in the field of image understanding. Under unsupervised conditions, different images and instances always have variable expressions, which make it difficult to achieve stable segmentation performance based on fixed rules or single type of feature. In order to solve this problem, the research proposes an unsupervised foreground segmentation method based on semantic-apparent feature fusion (SAFF). Here, we found that key regions of foreground object can be accurately responded via semantic features, while apparent features (represented by saliency and edge) provide richer detailed expression. To combine the advantages of the two type of features, an encoding method for unary region features and binary context features is established, which realizes a comprehensive description of the two types of expressions. Then, a method for adaptive parameter learning is put forward to calculate the most suitable feature weights and generate foreground confidence score map. Furthermore, segmentation network is used to learn foreground common features from different instances. By fusing semantic and apparent features, as well as cascading the modules of intra-image adaptive feature weight learning and inter-image common feature learning, the research achieves performance that significantly exceeds baselines on the PASCAL VOC 2012 dataset.