 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Shift Distillation for Diffusion Mode Seeking
Feb 21, 2025We present mean-shift distillation, a novel diffusion distillation technique that provides a provably good proxy for the gradient of the diffusion output distribution. This is derived directly from mean-shift mode seeking on the distribution, and we show that its extrema are aligned with the modes. We further derive an efficient product distribution sampling procedure to evaluate the gradient. Our method is formulated as a drop-in replacement for score distillation sampling (SDS), requiring neither model retraining nor extensive modification of the sampling procedure. We show that it exhibits superior mode alignment as well as improved convergence in both synthetic and practical setups, yielding higher-fidelity results when applied to both text-to-image and text-to-3D applications with Stable Diffusion.
NIVeL: Neural Implicit Vector Layers for Text-to-Vector Generation
May 24, 2024



The success of denoising diffusion models in representing rich data distributions over 2D raster images has prompted research on extending them to other data representations, such as vector graphics. Unfortunately due to their variable structure and scarcity of vector training data, directly applying diffusion models on this domain remains a challenging problem. Using workarounds like optimization via Score Distillation Sampling (SDS) is also fraught with difficulty, as vector representations are non trivial to directly optimize and tend to result in implausible geometries such as redundant or self-intersecting shapes. NIVeL addresses these challenges by reinterpreting the problem on an alternative, intermediate domain which preserves the desirable properties of vector graphics -- mainly sparsity of representation and resolution-independence. This alternative domain is based on neural implicit fields expressed in a set of decomposable, editable layers. Based on our experiments, NIVeL produces text-to-vector graphics results of significantly better quality than the state-of-the-art.
Im2Vec: Synthesizing Vector Graphics without Vector Supervision
Feb 04, 2021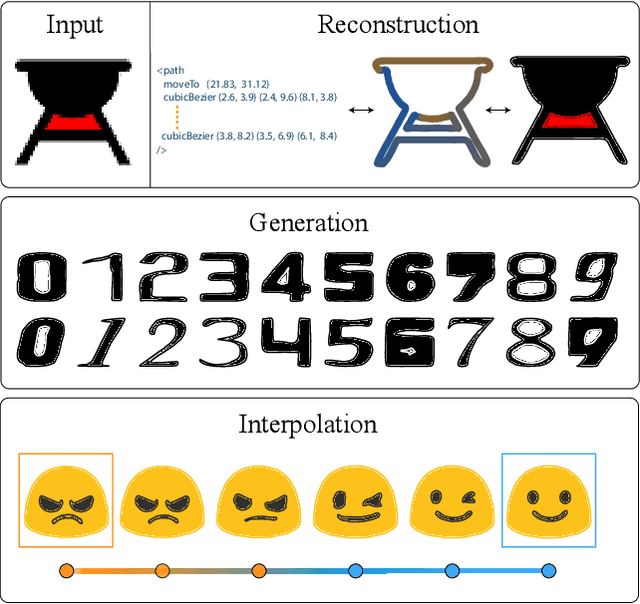
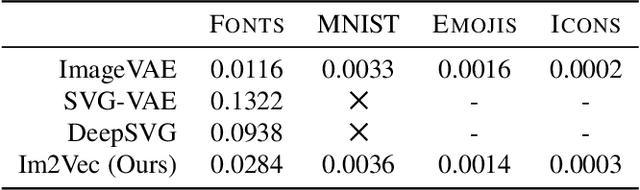

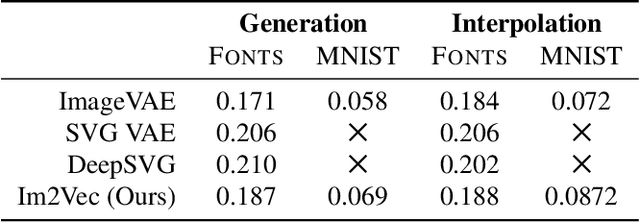
Vector graphics are widely used to represent fonts, logos, digital artworks, and graphic designs. But, while a vast body of work has focused on generative algorithms for raster images, only a handful of options exists for vector graphics. One can always rasterize the input graphic and resort to image-based generative approaches, but this negates the advantages of the vector representation. The current alternative is to use specialized models that require explicit supervision on the vector graphics representation at training time. This is not ideal because large-scale high quality vector-graphics datasets are difficult to obtain. Furthermore, the vector representation for a given design is not unique, so models that supervise on the vector representation are unnecessarily constrained. Instead, we propose a new neural network that can generate complex vector graphics with varying topologies, and only requires indirect supervision from readily-available raster training images (i.e., with no vector counterparts). To enable this, we use a differentiable rasterization pipeline that renders the generated vector shapes and composites them together onto a raster canvas. We demonstrate our method on a range of datasets, and provide comparison with state-of-the-art SVG-VAE and DeepSVG, both of which require explicit vector graphics supervision. Finally, we also demonstrate our approach on the MNIST dataset, for which no groundtruth vector representation is available. Source code, datasets, and more results are available at http://geometry.cs.ucl.ac.uk/projects/2020/Im2Vec/
Texture Mixer: A Network for Controllable Synthesis and Interpolation of Texture
Jan 11, 2019
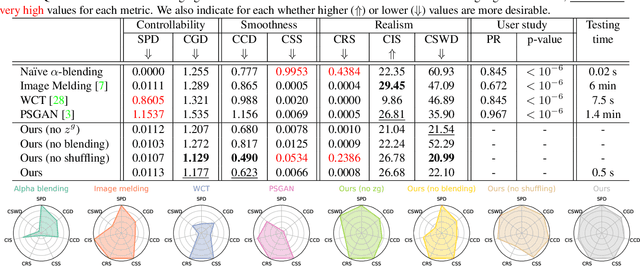
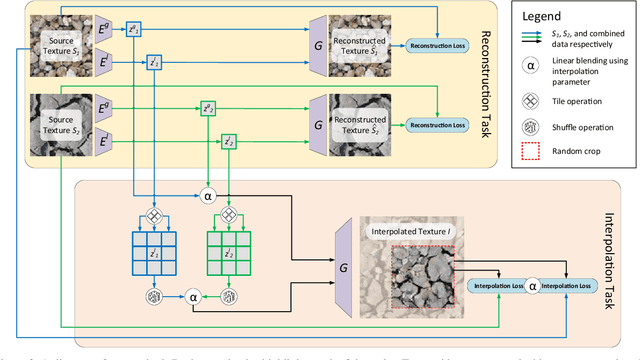

This paper addresses the problem of interpolating visual textures. We formulate the problem of texture interpolation by requiring (1) by-example controllability and (2) realistic and smooth interpolation among an arbitrary number of texture samples. To solve it we propose a neural network trained simultaneously on a reconstruction task and a generation task, which can project texture examples onto a latent space where they can be linearly interpolated and reprojected back onto the image domain, thus ensuring both intuitive control and realistic results. We show several additional applications including texture brushing and texture dissolve, and show our method outperforms a number of baselines according to a comprehensive suite of metrics as well as a user study.