 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Soccer Scene Analysis with Masked Pre-Training
Dec 22, 2025In this work we propose a multi-modal architecture for analyzing soccer scenes from tactical camera footage, with a focus on three core tasks: ball trajectory inference, ball state classification, and ball possessor identification. To this end, our solution integrates three distinct input modalities (player trajectories, player types and image crops of individual players) into a unified framework that processes spatial and temporal dynamics using a cascade of sociotemporal transformer blocks. Unlike prior methods, which rely heavily on accurate ball tracking or handcrafted heuristics, our approach infers the ball trajectory without direct access to its past or future positions, and robustly identifies the ball state and ball possessor under noisy or occluded conditions from real top league matches. We also introduce CropDrop, a modality-specific masking pre-training strategy that prevents over-reliance on image features and encourages the model to rely on cross-modal patterns during pre-training. We show the effectiveness of our approach on a large-scale dataset providing substantial improvements over state-of-the-art baselines in all tasks. Our results highlight the benefits of combining structured and visual cues in a transformer-based architecture, and the importance of realistic masking strategies in multi-modal learning.
JointDiff: Bridging Continuous and Discrete in Multi-Agent Trajectory Generation
Sep 26, 2025Generative models often treat continuous data and discrete events as separate processes, creating a gap in modeling complex systems where they interact synchronously. To bridge this gap, we introduce JointDiff, a novel diffusion framework designed to unify these two processes by simultaneously generating continuous spatio-temporal data and synchronous discrete events. We demonstrate its efficacy in the sports domain by simultaneously modeling multi-agent trajectories and key possession events. This joint modeling is validated with non-controllable generation and two novel controllable generation scenarios: weak-possessor-guidance, which offers flexible semantic control over game dynamics through a simple list of intended ball possessors, and text-guidance, which enables fine-grained, language-driven generation. To enable the conditioning with these guidance signals, we introduce CrossGuid, an effective conditioning operation for multi-agent domains. We also share a new unified sports benchmark enhanced with textual descriptions for soccer and football datasets. JointDiff achieves state-of-the-art performance, demonstrating that joint modeling is crucial for building realistic and controllable generative models for interactive systems.
Unified Uncertainty-Aware Diffusion for Multi-Agent Trajectory Modeling
Mar 24, 2025Multi-agent trajectory modeling has primarily focused on forecasting future states, often overlooking broader tasks like trajectory completion, which are crucial for real-world applications such as correcting tracking data. Existing methods also generally predict agents' states without offering any state-wise measure of uncertainty. Moreover, popular multi-modal sampling methods lack any error probability estimates for each generated scene under the same prior observations, making it difficult to rank the predictions during inference time. We introduce U2Diff, a \textbf{unified} diffusion model designed to handle trajectory completion while providing state-wise \textbf{uncertainty} estimates jointly. This uncertainty estimation is achieved by augmenting the simple denoising loss with the negative log-likelihood of the predicted noise and propagating latent space uncertainty to the real state space. Additionally, we incorporate a Rank Neural Network in post-processing to enable \textbf{error probability} estimation for each generated mode, demonstrating a strong correlation with the error relative to ground truth. Our method outperforms the state-of-the-art solutions in trajectory completion and forecasting across four challenging sports datasets (NBA, Basketball-U, Football-U, Soccer-U), highlighting the effectiveness of uncertainty and error probability estimation. Video at https://youtu.be/ngw4D4eJToE
TranSPORTmer: A Holistic Approach to Trajectory Understanding in Multi-Agent Sports
Oct 23, 2024Understanding trajectories in multi-agent scenarios requires addressing various tasks, including predicting future movements, imputing missing observations, inferring the status of unseen agents, and classifying different global states. Traditional data-driven approaches often handle these tasks separately with specialized models. We introduce TranSPORTmer, a unified transformer-based framework capable of addressing all these tasks, showcasing its application to the intricate dynamics of multi-agent sports scenarios like soccer and basketball. Using Set Attention Blocks, TranSPORTmer effectively captures temporal dynamics and social interactions in an equivariant manner. The model's tasks are guided by an input mask that conceals missing or yet-to-be-predicted observations. Additionally, we introduce a CLS extra agent to classify states along soccer trajectories, including passes, possessions, uncontrolled states, and out-of-play intervals, contributing to an enhancement in modeling trajectories. Evaluations on soccer and basketball datasets show that TranSPORTmer outperforms state-of-the-art task-specific models in player forecasting, player forecasting-imputation, ball inference, and ball imputation. https://youtu.be/8VtSRm8oGoE
FootBots: A Transformer-based Architecture for Motion Prediction in Soccer
Jun 28, 2024Motion prediction in soccer involves capturing complex dynamics from player and ball interactions. We present FootBots, an encoder-decoder transformer-based architecture addressing motion prediction and conditioned motion prediction through equivariance properties. FootBots captures temporal and social dynamics using set attention blocks and multi-attention block decoder. Our evaluation utilizes two datasets: a real soccer dataset and a tailored synthetic one. Insights from the synthetic dataset highlight the effectiveness of FootBots' social attention mechanism and the significance of conditioned motion prediction. Empirical results on real soccer data demonstrate that FootBots outperforms baselines in motion prediction and excels in conditioned tasks, such as predicting the players based on the ball position, predicting the offensive (defensive) team based on the ball and the defensive (offensive) team, and predicting the ball position based on all players. Our evaluation connects quantitative and qualitative findings. https://youtu.be/9kaEkfzG3L8
Fracking Deep Convolutional Image Descriptors
Feb 25, 2015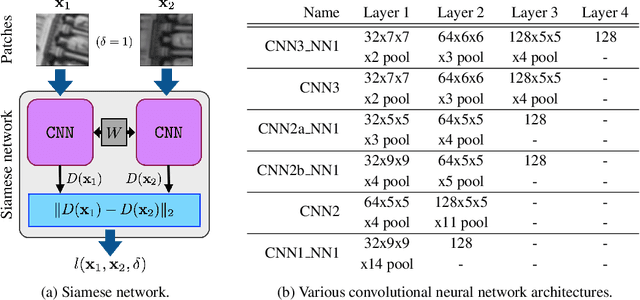


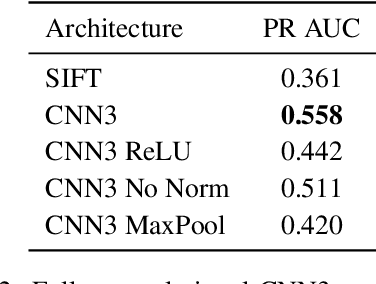
In this paper we propose a novel framework for learning local image descriptors in a discriminative manner. For this purpose we explore a siamese architecture of Deep Convolutional Neural Networks (CNN), with a Hinge embedding loss on the L2 distance between descriptors. Since a siamese architecture uses pairs rather than single image patches to train, there exist a large number of positive samples and an exponential number of negative samples. We propose to explore this space with a stochastic sampling of the training set, in combination with an aggressive mining strategy over both the positive and negative samples which we denote as "fracking". We perform a thorough evaluation of the architecture hyper-parameters, and demonstrate large performance gains compared to both standard CNN learning strategies, hand-crafted image descriptors like SIFT, and the state-of-the-art on learned descriptors: up to 2.5x vs SIFT and 1.5x vs the state-of-the-art in terms of the area under the curve (AUC) of the Precision-Recall curve.