 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFTDebias : Capturing debiasing information using PEFTs
Dec 01, 2023The increasing use of foundation models highlights the urgent need to address and eliminate implicit biases present in them that arise during pretraining. In this paper, we introduce PEFTDebias, a novel approach that employs parameter-efficient fine-tuning (PEFT) to mitigate the biases within foundation models. PEFTDebias consists of two main phases: an upstream phase for acquiring debiasing parameters along a specific bias axis, and a downstream phase where these parameters are incorporated into the model and frozen during the fine-tuning process. By evaluating on four datasets across two bias axes namely gender and race, we find that downstream biases can be effectively reduced with PEFTs. In addition, we show that these parameters possess axis-specific debiasing characteristics, enabling their effective transferability in mitigating biases in various downstream tasks. To ensure reproducibility, we release the code to do our experiments.
CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code
Feb 10, 2023



Since the rise of neural models of code that can generate long expressions and statements rather than a single next-token, one of the major problems has been reliably evaluating their generated output. In this paper, we propose CodeBERTScore: an automatic evaluation metric for code generation, which builds on BERTScore (Zhang et al., 2020). Instead of measuring exact token matching as BLEU, CodeBERTScore computes a soft similarity score between each token in the generated code and in the reference code, using the contextual encodings of large pretrained models. Further, instead of encoding only the generated tokens as in BERTScore, CodeBERTScore also encodes the programmatic context surrounding the generated code. We perform an extensive evaluation of CodeBERTScore across four programming languages. We find that CodeBERTScore achieves a higher correlation with human preference and with functional correctness than all existing metrics. That is, generated code that receives a higher score by CodeBERTScore is more likely to be preferred by humans, as well as to function correctly when executed. Finally, while CodeBERTScore can be used with a multilingual CodeBERT as its base model, we release five language-specific pretrained models to use with our publicly available code at https://github.com/neulab/code-bert-score . Our language-specific models have been downloaded more than 25,000 times from the Huggingface Hub.
Illumination-invariant Face recognition by fusing thermal and visual images via gradient transfer
Feb 23, 2019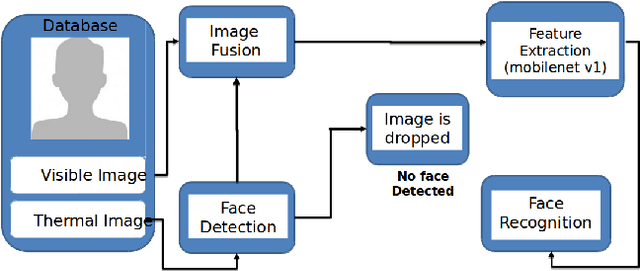

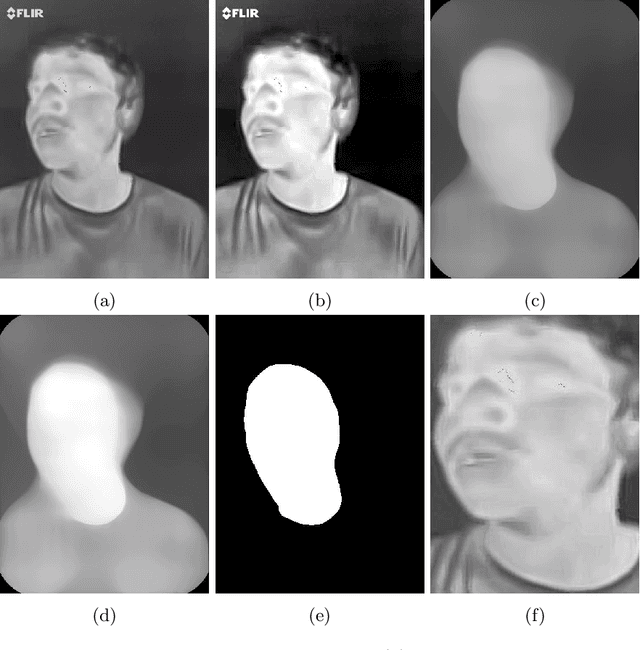
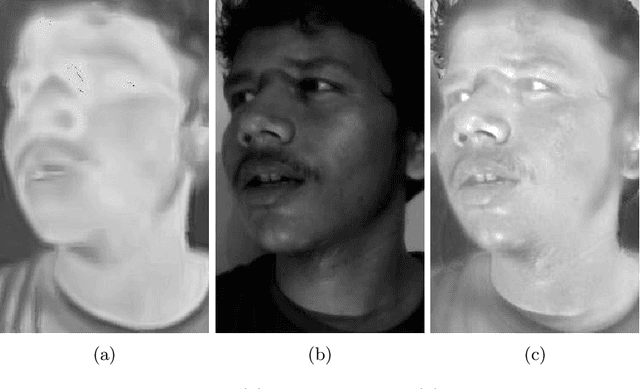
Face recognition in real life situations like low illumination condition is still an open challenge in biometric security. It is well established that the state-of-the-art methods in face recognition provide low accuracy in the case of poor illumination. In this work, we propose an algorithm for a more robust illumination invariant face recognition using a multi-modal approach. We propose a new dataset consisting of aligned faces of thermal and visual images of a hundred subjects. We then apply face detection on thermal images using the biggest blob extraction method and apply them for fusing images of different modalities for the purpose of face recognition. An algorithm is proposed to implement fusion of thermal and visual images. We reason for why relying on only one modality can give erroneous results. We use a lighter and faster CNN model called MobileNet for the purpose of face recognition with faster inferencing and to be able to be use it in real time biometric systems. We test our proposed method on our own created dataset to show that real-time face recognition on fused images shows far better results than using visual or thermal images separately.