 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational AI Threads for Visualizing Multidimensional Datasets
Nov 09, 2023



Generative Large Language Models (LLMs) show potential in data analysis, yet their full capabilities remain uncharted. Our work explores the capabilities of LLMs for creating and refining visualizations via conversational interfaces. We used an LLM to conduct a re-analysis of a prior Wizard-of-Oz study examining the use of chatbots for conducting visual analysis. We surfaced the strengths and weaknesses of LLM-driven analytic chatbots, finding that they fell short in supporting progressive visualization refinements. From these findings, we developed AI Threads, a multi-threaded analytic chatbot that enables analysts to proactively manage conversational context and improve the efficacy of its outputs. We evaluate its usability through a crowdsourced study (n=40) and in-depth interviews with expert analysts (n=10). We further demonstrate the capabilities of AI Threads on a dataset outside the LLM's training corpus. Our findings show the potential of LLMs while also surfacing challenges and fruitful avenues for future research.
Eliciting Model Steering Interactions from Users via Data and Visual Design Probes
Oct 12, 2023
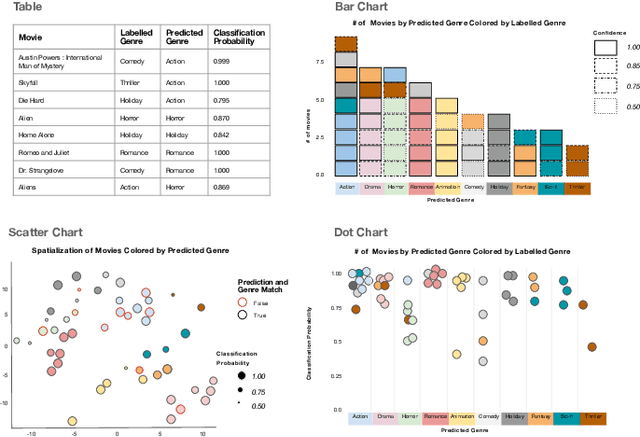


Domain experts increasingly use automated data science tools to incorporate machine learning (ML) models in their work but struggle to "debug" these models when they are incorrect. For these experts, semantic interactions can provide an accessible avenue to guide and refine ML models without having to programmatically dive into its technical details. In this research, we conduct an elicitation study using data and visual design probes to examine if and how experts with a spectrum of ML expertise use semantic interactions to update a simple classification model. We use our design probes to facilitate an interactive dialogue with 20 participants and codify their interactions as a set of target-interaction pairs. Interestingly, our findings revealed that many targets of semantic interactions do not directly map to ML model parameters, but instead aim to augment the data a model uses for training. We also identify reasons that participants would hesitate to interact with ML models, including burdens of cognitive load and concerns of injecting bias. Unexpectedly participants also saw the value of using semantic interactions to work collaboratively with members of their team. Participants with less ML expertise found this to be a useful mechanism for communicating their concerns to ML experts. This was an especially important observation, as our study also shows the different needs that correspond to diverse ML expertise. Collectively, we demonstrate that design probes are effective tools for proactively gathering the affordances that should be offered in an interactive machine learning system.
Interactive Model Cards: A Human-Centered Approach to Model Documentation
May 05, 2022
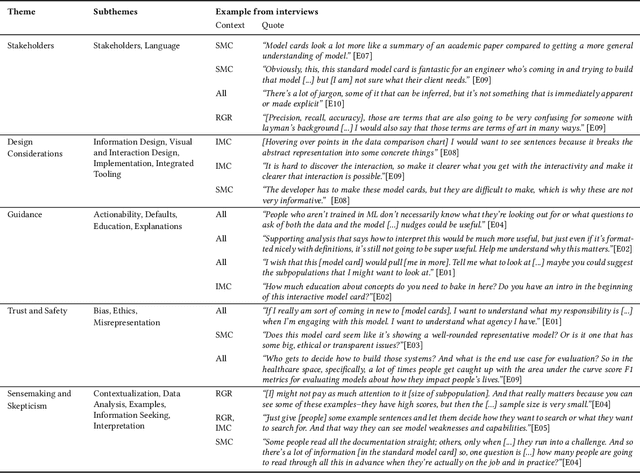

Deep learning models for natural language processing (NLP) are increasingly adopted and deployed by analysts without formal training in NLP or machine learning (ML). However, the documentation intended to convey the model's details and appropriate use is tailored primarily to individuals with ML or NLP expertise. To address this gap, we conduct a design inquiry into interactive model cards, which augment traditionally static model cards with affordances for exploring model documentation and interacting with the models themselves. Our investigation consists of an initial conceptual study with experts in ML, NLP, and AI Ethics, followed by a separate evaluative study with non-expert analysts who use ML models in their work. Using a semi-structured interview format coupled with a think-aloud protocol, we collected feedback from a total of 30 participants who engaged with different versions of standard and interactive model cards. Through a thematic analysis of the collected data, we identified several conceptual dimensions that summarize the strengths and limitations of standard and interactive model cards, including: stakeholders; design; guidance; understandability & interpretability; sensemaking & skepticism; and trust & safety. Our findings demonstrate the importance of carefully considered design and interactivity for orienting and supporting non-expert analysts using deep learning models, along with a need for consideration of broader sociotechnical contexts and organizational dynamics. We have also identified design elements, such as language, visual cues, and warnings, among others, that support interactivity and make non-interactive content accessible. We summarize our findings as design guidelines and discuss their implications for a human-centered approach towards AI/ML documentation.
Fits and Starts: Enterprise Use of AutoML and the Role of Humans in the Loop
Jan 12, 2021


AutoML systems can speed up routine data science work and make machine learning available to those without expertise in statistics and computer science. These systems have gained traction in enterprise settings where pools of skilled data workers are limited. In this study, we conduct interviews with 29 individuals from organizations of different sizes to characterize how they currently use, or intend to use, AutoML systems in their data science work. Our investigation also captures how data visualization is used in conjunction with AutoML systems. Our findings identify three usage scenarios for AutoML that resulted in a framework summarizing the level of automation desired by data workers with different levels of expertise. We surfaced the tension between speed and human oversight and found that data visualization can do a poor job balancing the two. Our findings have implications for the design and implementation of human-in-the-loop visual analytics approaches.
User Ex Machina : Simulation as a Design Probe in Human-in-the-Loop Text Analytics
Jan 06, 2021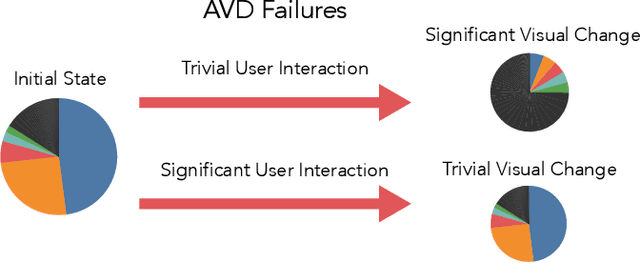

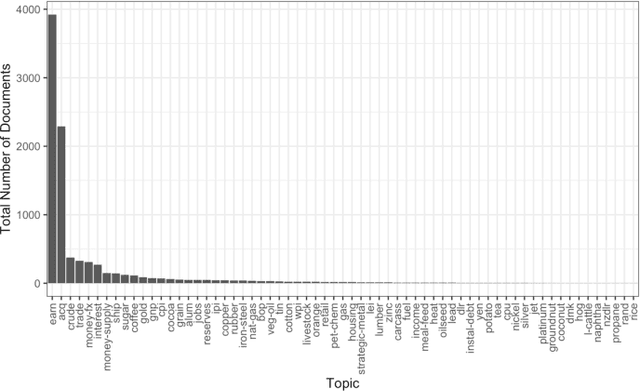
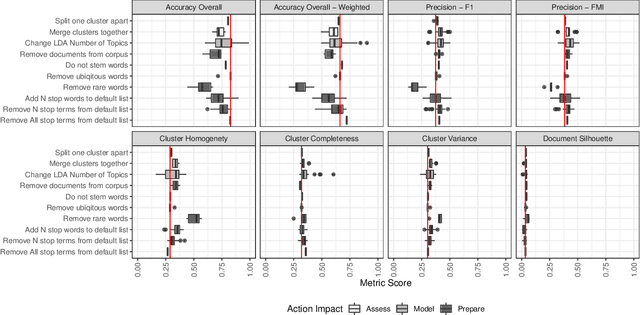
Topic models are widely used analysis techniques for clustering documents and surfacing thematic elements of text corpora. These models remain challenging to optimize and often require a "human-in-the-loop" approach where domain experts use their knowledge to steer and adjust. However, the fragility, incompleteness, and opacity of these models means even minor changes could induce large and potentially undesirable changes in resulting model. In this paper we conduct a simulation-based analysis of human-centered interactions with topic models, with the objective of measuring the sensitivity of topic models to common classes of user actions. We find that user interactions have impacts that differ in magnitude but often negatively affect the quality of the resulting modelling in a way that can be difficult for the user to evaluate. We suggest the incorporation of sensitivity and "multiverse" analyses to topic model interfaces to surface and overcome these deficiencies.