 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Model Steering Interactions from Users via Data and Visual Design Probes
Oct 12, 2023Domain experts increasingly use automated data science tools to incorporate machine learning (ML) models in their work but struggle to "debug" these models when they are incorrect. For these experts, semantic interactions can provide an accessible avenue to guide and refine ML models without having to programmatically dive into its technical details. In this research, we conduct an elicitation study using data and visual design probes to examine if and how experts with a spectrum of ML expertise use semantic interactions to update a simple classification model. We use our design probes to facilitate an interactive dialogue with 20 participants and codify their interactions as a set of target-interaction pairs. Interestingly, our findings revealed that many targets of semantic interactions do not directly map to ML model parameters, but instead aim to augment the data a model uses for training. We also identify reasons that participants would hesitate to interact with ML models, including burdens of cognitive load and concerns of injecting bias. Unexpectedly participants also saw the value of using semantic interactions to work collaboratively with members of their team. Participants with less ML expertise found this to be a useful mechanism for communicating their concerns to ML experts. This was an especially important observation, as our study also shows the different needs that correspond to diverse ML expertise. Collectively, we demonstrate that design probes are effective tools for proactively gathering the affordances that should be offered in an interactive machine learning system.
Optimal Sub-sampling with Influence Functions
Sep 06, 2017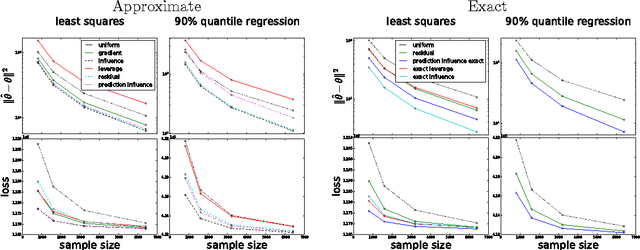
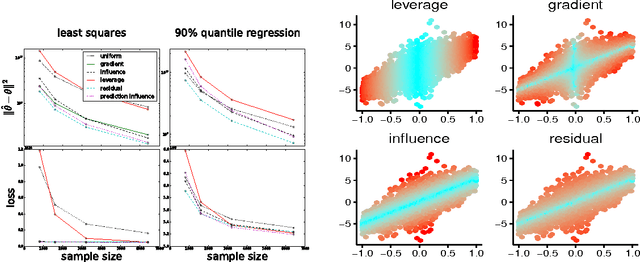
Sub-sampling is a common and often effective method to deal with the computational challenges of large datasets. However, for most statistical models, there is no well-motivated approach for drawing a non-uniform subsample. We show that the concept of an asymptotically linear estimator and the associated influence function leads to optimal sampling procedures for a wide class of popular models. Furthermore, for linear regression models which have well-studied procedures for non-uniform sub-sampling, we show our optimal influence function based method outperforms previous approaches. We empirically show the improved performance of our method on real datasets.
Portfolio Allocation for Bayesian Optimization
Mar 07, 2011



Bayesian optimization with Gaussian processes has become an increasingly popular tool in the machine learning community. It is efficient and can be used when very little is known about the objective function, making it popular in expensive black-box optimization scenarios. It uses Bayesian methods to sample the objective efficiently using an acquisition function which incorporates the model's estimate of the objective and the uncertainty at any given point. However, there are several different parameterized acquisition functions in the literature, and it is often unclear which one to use. Instead of using a single acquisition function, we adopt a portfolio of acquisition functions governed by an online multi-armed bandit strategy. We propose several portfolio strategies, the best of which we call GP-Hedge, and show that this method outperforms the best individual acquisition function. We also provide a theoretical bound on the algorithm's performance.
A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning
Dec 12, 2010

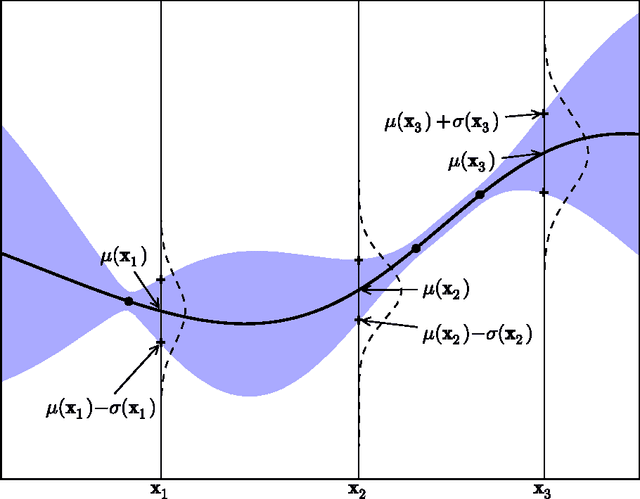

We present a tutorial on Bayesian optimization, a method of finding the maximum of expensive cost functions. Bayesian optimization employs the Bayesian technique of setting a prior over the objective function and combining it with evidence to get a posterior function. This permits a utility-based selection of the next observation to make on the objective function, which must take into account both exploration (sampling from areas of high uncertainty) and exploitation (sampling areas likely to offer improvement over the current best observation). We also present two detailed extensions of Bayesian optimization, with experiments---active user modelling with preferences, and hierarchical reinforcement learning---and a discussion of the pros and cons of Bayesian optimization based on our experiences.