 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Model Steering Interactions from Users via Data and Visual Design Probes
Oct 12, 2023Domain experts increasingly use automated data science tools to incorporate machine learning (ML) models in their work but struggle to "debug" these models when they are incorrect. For these experts, semantic interactions can provide an accessible avenue to guide and refine ML models without having to programmatically dive into its technical details. In this research, we conduct an elicitation study using data and visual design probes to examine if and how experts with a spectrum of ML expertise use semantic interactions to update a simple classification model. We use our design probes to facilitate an interactive dialogue with 20 participants and codify their interactions as a set of target-interaction pairs. Interestingly, our findings revealed that many targets of semantic interactions do not directly map to ML model parameters, but instead aim to augment the data a model uses for training. We also identify reasons that participants would hesitate to interact with ML models, including burdens of cognitive load and concerns of injecting bias. Unexpectedly participants also saw the value of using semantic interactions to work collaboratively with members of their team. Participants with less ML expertise found this to be a useful mechanism for communicating their concerns to ML experts. This was an especially important observation, as our study also shows the different needs that correspond to diverse ML expertise. Collectively, we demonstrate that design probes are effective tools for proactively gathering the affordances that should be offered in an interactive machine learning system.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021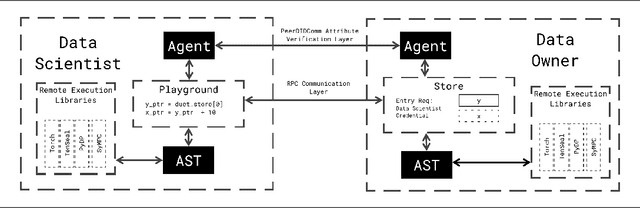
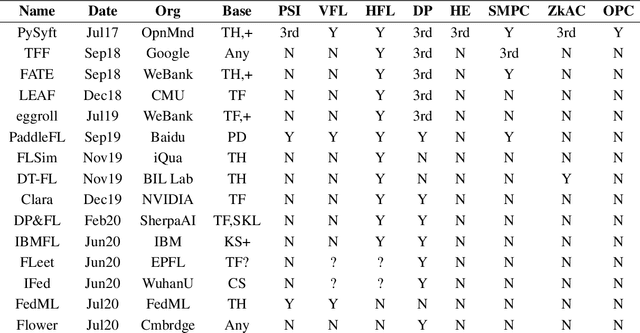
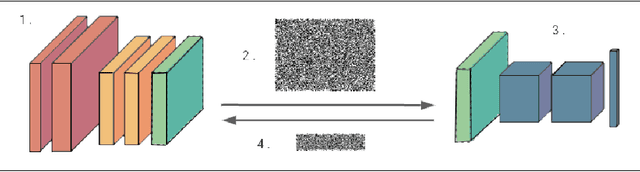
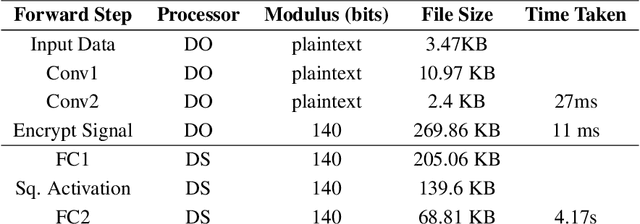
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.