 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Positional Bias of Faithfulness for Long-form Summarization
Paper and Code
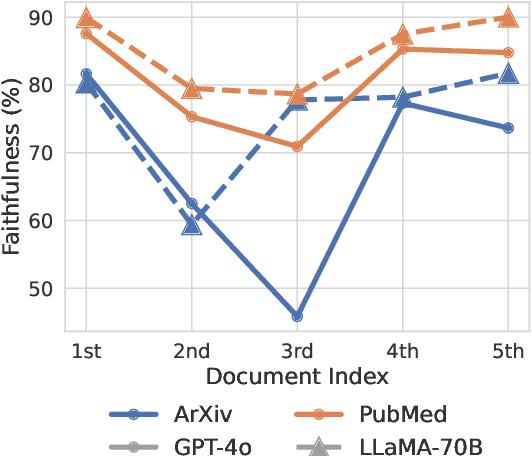

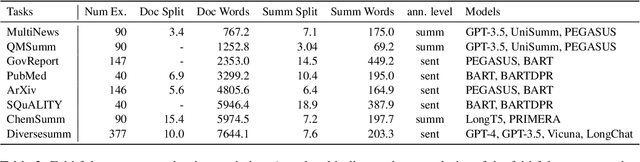

Large Language Models (LLMs) often exhibit positional bias in long-context settings, under-attending to information in the middle of inputs. We investigate the presence of this bias in long-form summarization, its impact on faithfulness, and various techniques to mitigate this bias. To consistently evaluate faithfulness, we first compile a benchmark of eight human-annotated long-form summarization datasets and perform a meta-evaluation of faithfulness metrics. We show that LLM-based faithfulness metrics, though effective with full-context inputs, remain sensitive to document order, indicating positional bias. Analyzing LLM-generated summaries across six datasets, we find a "U-shaped" trend in faithfulness, where LLMs faithfully summarize the beginning and end of documents but neglect middle content. Perturbing document order similarly reveals models are less faithful when important documents are placed in the middle of the input. We find that this behavior is partly due to shifting focus with context length: as context increases, summaries become less faithful, but beyond a certain length, faithfulness improves as the model focuses on the end. Finally, we experiment with different generation techniques to reduce positional bias and find that prompting techniques effectively direct model attention to specific positions, whereas more sophisticated approaches offer limited improvements. Our data and code are available in https://github.com/meetdavidwan/longformfact.