 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid Spatial Understanding: A Dataset for Textual Spatial Reasoning over Grids, Embodied Settings, and Coordinate Structures
Mar 18, 2026We introduce GSU, a text-only grid dataset to evaluate the spatial reasoning capabilities of LLMs over 3 core tasks: navigation, object localization, and structure composition. By forgoing visual inputs, isolating spatial reasoning from perception, we show that while most models grasp basic grid concepts, they struggle with frames of reference relative to an embodied agent and identifying 3D shapes from coordinate lists. We also find that exposure to a visual modality does not provide a generalizable understanding of 3D space that VLMs are able to utilize for these tasks. Finally, we show that while the very latest frontier models can solve the provided tasks (though harder variants may still stump them), fully fine-tuning a small LM or LORA fine-tuning a small LLM show potential to match frontier model performance, suggesting an avenue for specialized embodied agents.
RAG-RL: Advancing Retrieval-Augmented Generation via RL and Curriculum Learning
Mar 17, 2025Recent research highlights the challenges retrieval models face in retrieving useful contexts and the limitations of generation models in effectively utilizing those contexts in retrieval-augmented generation (RAG) settings. To address these challenges, we introduce RAG-RL, the first reasoning language model (RLM) specifically trained for RAG. RAG-RL demonstrates that stronger answer generation models can identify relevant contexts within larger sets of retrieved information -- thereby alleviating the burden on retrievers -- while also being able to utilize those contexts more effectively. Moreover, we show that curriculum design in the reinforcement learning (RL) post-training process is a powerful approach to enhancing model performance. We benchmark our method on two open-domain question-answering datasets and achieve state-of-the-art results, surpassing previous SOTA generative reader models. In addition, we offers empirical insights into various curriculum learning strategies, providing a deeper understanding of their impact on model performance.
Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition Extraction
May 24, 2023Mathematical symbol definition extraction is important for improving scholarly reading interfaces and scholarly information extraction (IE). However, the task poses several challenges: math symbols are difficult to process as they are not composed of natural language morphemes; and scholarly papers often contain sentences that require resolving complex coordinate structures. We present SymDef, an English language dataset of 5,927 sentences from full-text scientific papers where each sentence is annotated with all mathematical symbols linked with their corresponding definitions. This dataset focuses specifically on complex coordination structures such as "respectively" constructions, which often contain overlapping definition spans. We also introduce a new definition extraction method that masks mathematical symbols, creates a copy of each sentence for each symbol, specifies a target symbol, and predicts its corresponding definition spans using slot filling. Our experiments show that our definition extraction model significantly outperforms RoBERTa and other strong IE baseline systems by 10.9 points with a macro F1 score of 84.82. With our dataset and model, we can detect complex definitions in scholarly documents to make scientific writing more readable.
Document-Level Definition Detection in Scholarly Documents: Existing Models, Error Analyses, and Future Directions
Oct 11, 2020
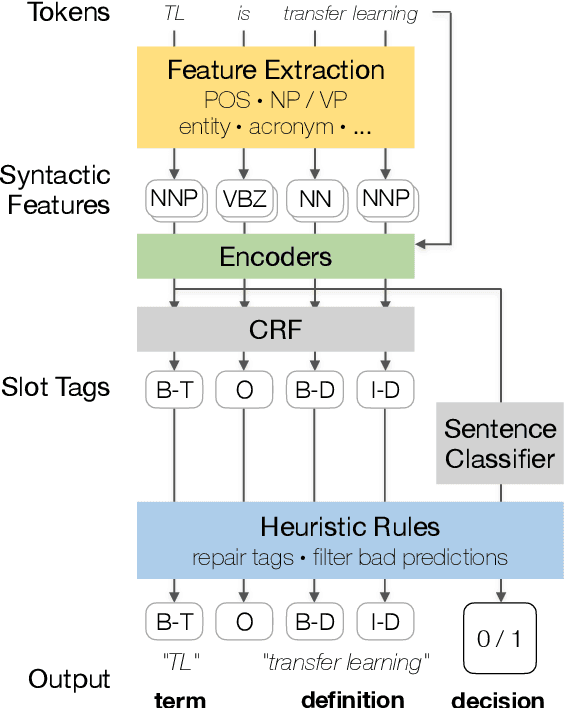
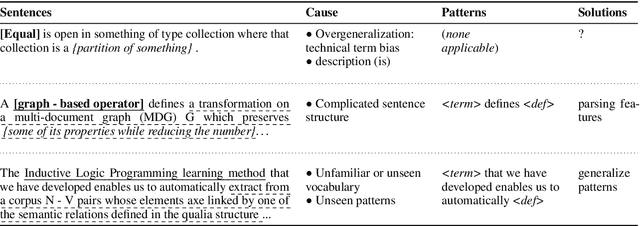

The task of definition detection is important for scholarly papers, because papers often make use of technical terminology that may be unfamiliar to readers. Despite prior work on definition detection, current approaches are far from being accurate enough to use in real-world applications. In this paper, we first perform in-depth error analysis of the current best performing definition detection system and discover major causes of errors. Based on this analysis, we develop a new definition detection system, HEDDEx, that utilizes syntactic features, transformer encoders, and heuristic filters, and evaluate it on a standard sentence-level benchmark. Because current benchmarks evaluate randomly sampled sentences, we propose an alternative evaluation that assesses every sentence within a document. This allows for evaluating recall in addition to precision. HEDDEx outperforms the leading system on both the sentence-level and the document-level tasks, by 12.7 F1 points and 14.4 F1 points, respectively. We note that performance on the high-recall document-level task is much lower than in the standard evaluation approach, due to the necessity of incorporation of document structure as features. We discuss remaining challenges in document-level definition detection, ideas for improvements, and potential issues for the development of reading aid applications.