 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen do neural ordinary differential equations generalize on complex networks?
Feb 09, 2026Neural ordinary differential equations (neural ODEs) can effectively learn dynamical systems from time series data, but their behavior on graph-structured data remains poorly understood, especially when applied to graphs with different size or structure than encountered during training. We study neural ODEs ($\mathtt{nODE}$s) with vector fields following the Barabási-Barzel form, trained on synthetic data from five common dynamical systems on graphs. Using the $\mathbb{S}^1$-model to generate graphs with realistic and tunable structure, we find that degree heterogeneity and the type of dynamical system are the primary factors in determining $\mathtt{nODE}$s' ability to generalize across graph sizes and properties. This extends to $\mathtt{nODE}$s' ability to capture fixed points and maintain performance amid missing data. Average clustering plays a secondary role in determining $\mathtt{nODE}$ performance. Our findings highlight $\mathtt{nODE}$s as a powerful approach to understanding complex systems but underscore challenges emerging from degree heterogeneity and clustering in realistic graphs.
Designing Ecosystems of Intelligence from First Principles
Dec 02, 2022


This white paper lays out a vision of research and development in the field of artificial intelligence for the next decade (and beyond). Its denouement is a cyber-physical ecosystem of natural and synthetic sense-making, in which humans are integral participants$\unicode{x2014}$what we call ''shared intelligence''. This vision is premised on active inference, a formulation of adaptive behavior that can be read as a physics of intelligence, and which inherits from the physics of self-organization. In this context, we understand intelligence as the capacity to accumulate evidence for a generative model of one's sensed world$\unicode{x2014}$also known as self-evidencing. Formally, this corresponds to maximizing (Bayesian) model evidence, via belief updating over several scales: i.e., inference, learning, and model selection. Operationally, this self-evidencing can be realized via (variational) message passing or belief propagation on a factor graph. Crucially, active inference foregrounds an existential imperative of intelligent systems; namely, curiosity or the resolution of uncertainty. This same imperative underwrites belief sharing in ensembles of agents, in which certain aspects (i.e., factors) of each agent's generative world model provide a common ground or frame of reference. Active inference plays a foundational role in this ecology of belief sharing$\unicode{x2014}$leading to a formal account of collective intelligence that rests on shared narratives and goals. We also consider the kinds of communication protocols that must be developed to enable such an ecosystem of intelligences and motivate the development of a shared hyper-spatial modeling language and transaction protocol, as a first$\unicode{x2014}$and key$\unicode{x2014}$step towards such an ecology.
pymdp: A Python library for active inference in discrete state spaces
Jan 11, 2022Active inference is an account of cognition and behavior in complex systems which brings together action, perception, and learning under the theoretical mantle of Bayesian inference. Active inference has seen growing applications in academic research, especially in fields that seek to model human or animal behavior. While in recent years, some of the code arising from the active inference literature has been written in open source languages like Python and Julia, to-date, the most popular software for simulating active inference agents is the DEM toolbox of SPM, a MATLAB library originally developed for the statistical analysis and modelling of neuroimaging data. Increasing interest in active inference, manifested both in terms of sheer number as well as diversifying applications across scientific disciplines, has thus created a need for generic, widely-available, and user-friendly code for simulating active inference in open-source scientific computing languages like Python. The Python package we present here, pymdp (see https://github.com/infer-actively/pymdp), represents a significant step in this direction: namely, we provide the first open-source package for simulating active inference with partially-observable Markov Decision Processes or POMDPs. We review the package's structure and explain its advantages like modular design and customizability, while providing in-text code blocks along the way to demonstrate how it can be used to build and run active inference processes with ease. We developed pymdp to increase the accessibility and exposure of the active inference framework to researchers, engineers, and developers with diverse disciplinary backgrounds. In the spirit of open-source software, we also hope that it spurs new innovation, development, and collaboration in the growing active inference community.
Fast Model-Selection through Adapting Design of Experiments Maximizing Information Gain
Oct 23, 2018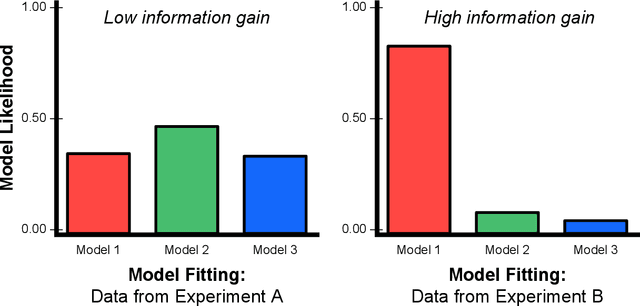

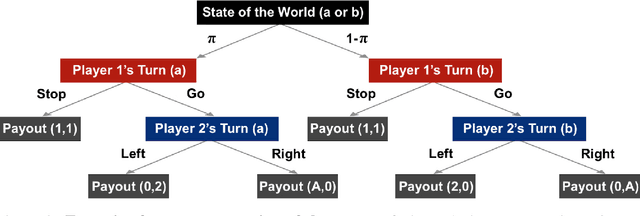
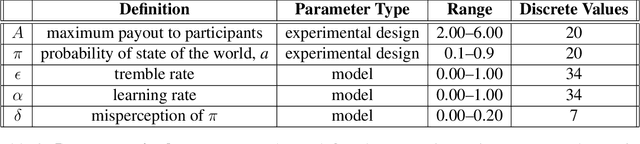
To perform model-selection efficiently, we must run informative experiments. Here, we extend a seminal method for designing Bayesian optimal experiments that maximize the information gained from data collected. We introduce two computational improvements that make the procedure tractable: a search algorithm from artificial intelligence and a sampling procedure shrinking the space of possible experiments to evaluate. We collected data for five different experimental designs of a simple imperfect information game and show that experiments optimized for information gain make model-selection possible (and cheaper). We compare the ability of the optimal experimental design to discriminate among competing models against the experimental designs chosen by a "wisdom of experts" prediction experiment. We find that a simple reinforcement learning model best explains human decision-making and that subject behavior is not adequately described by Bayesian Nash equilibrium. Our procedure is general and can be applied iteratively to lab, field and online experiments.