 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction Vectors in Large Language Models
Oct 23, 2023We report the presence of a simple neural mechanism that represents an input-output function as a vector within autoregressive transformer language models (LMs). Using causal mediation analysis on a diverse range of in-context-learning (ICL) tasks, we find that a small number attention heads transport a compact representation of the demonstrated task, which we call a function vector (FV). FVs are robust to changes in context, i.e., they trigger execution of the task on inputs such as zero-shot and natural text settings that do not resemble the ICL contexts from which they are collected. We test FVs across a range of tasks, models, and layers and find strong causal effects across settings in middle layers. We investigate the internal structure of FVs and find while that they often contain information that encodes the output space of the function, this information alone is not sufficient to reconstruct an FV. Finally, we test semantic vector composition in FVs, and find that to some extent they can be summed to create vectors that trigger new complex tasks. Taken together, our findings suggest that LLMs contain internal abstractions of general-purpose functions that can be invoked in a variety of contexts.
Summarizing, Simplifying, and Synthesizing Medical Evidence Using GPT-3 (with Varying Success)
May 11, 2023

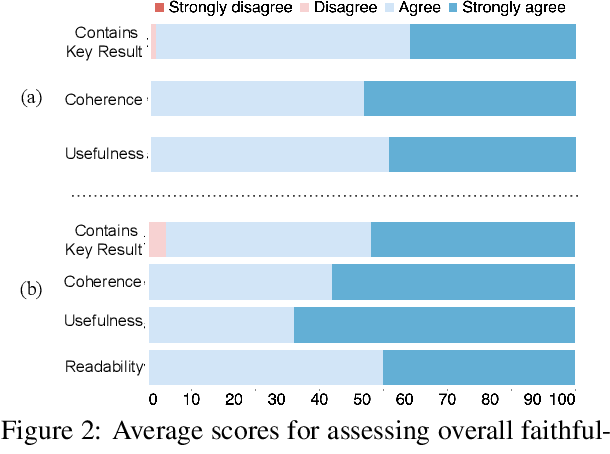

Large language models, particularly GPT-3, are able to produce high quality summaries of general domain news articles in few- and zero-shot settings. However, it is unclear if such models are similarly capable in more specialized, high-stakes domains such as biomedicine. In this paper, we enlist domain experts (individuals with medical training) to evaluate summaries of biomedical articles generated by GPT-3, given zero supervision. We consider both single- and multi-document settings. In the former, GPT-3 is tasked with generating regular and plain-language summaries of articles describing randomized controlled trials; in the latter, we assess the degree to which GPT-3 is able to \emph{synthesize} evidence reported across a collection of articles. We design an annotation scheme for evaluating model outputs, with an emphasis on assessing the factual accuracy of generated summaries. We find that while GPT-3 is able to summarize and simplify single biomedical articles faithfully, it struggles to provide accurate aggregations of findings over multiple documents. We release all data and annotations used in this work.