 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulness vs. Safety: Evaluating LLM Behavior Under Counterfactual Medical Evidence
Jan 17, 2026In high-stakes domains like medicine, it may be generally desirable for models to faithfully adhere to the context provided. But what happens if the context does not align with model priors or safety protocols? In this paper, we investigate how LLMs behave and reason when presented with counterfactual or even adversarial medical evidence. We first construct MedCounterFact, a counterfactual medical QA dataset that requires the models to answer clinical comparison questions (i.e., judge the efficacy of certain treatments, with evidence consisting of randomized controlled trials provided as context). In MedCounterFact, real-world medical interventions within the questions and evidence are systematically replaced with four types of counterfactual stimuli, ranging from unknown words to toxic substances. Our evaluation across multiple frontier LLMs on MedCounterFact reveals that in the presence of counterfactual evidence, existing models overwhelmingly accept such "evidence" at face value even when it is dangerous or implausible, and provide confident and uncaveated answers. While it may be prudent to draw a boundary between faithfulness and safety, our findings reveal that there exists no such boundary yet.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Measuring diversity of synthetic prompts and data generated with fine-grained persona prompting
May 23, 2025Fine-grained personas have recently been used for generating 'diverse' synthetic data for pre-training and supervised fine-tuning of Large Language Models (LLMs). In this work, we measure the diversity of persona-driven synthetically generated prompts and responses with a suite of lexical diversity and redundancy metrics. Firstly, we find that synthetic prompts/instructions are significantly less diverse than human-written ones. Next, we sample responses from LLMs of different sizes with fine-grained and coarse persona descriptions to investigate how much fine-grained detail in persona descriptions contribute to generated text diversity. We find that while persona-prompting does improve lexical diversity (especially with larger models), fine-grained detail in personas doesn't increase diversity noticeably.
Who Taught You That? Tracing Teachers in Model Distillation
Feb 10, 2025Model distillation -- using outputs from a large teacher model to teach a small student model -- is a practical means of creating efficient models for a particular task. We ask: Can we identify a students' teacher based on its outputs? Such "footprints" left by teacher LLMs would be interesting artifacts. Beyond this, reliable teacher inference may have practical implications as actors seek to distill specific capabilities of massive proprietary LLMs into deployed smaller LMs, potentially violating terms of service. We consider practical task distillation targets including summarization, question answering, and instruction-following. We assume a finite set of candidate teacher models, which we treat as blackboxes. We design discriminative models that operate over lexical features. We find that $n$-gram similarity alone is unreliable for identifying teachers, but part-of-speech (PoS) templates preferred by student models mimic those of their teachers.
Detection and Measurement of Syntactic Templates in Generated Text
Jun 28, 2024
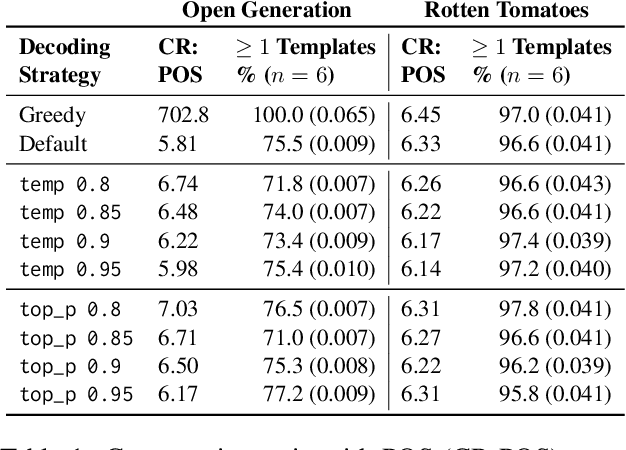

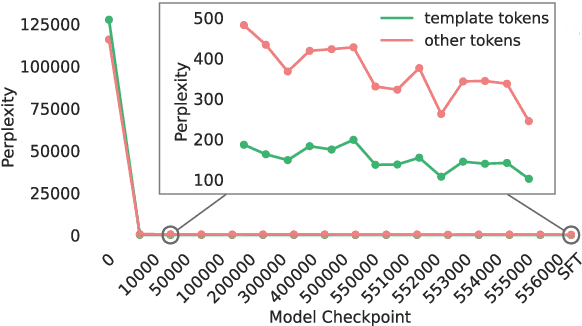
Recent work on evaluating the diversity of text generated by LLMs has focused on word-level features. Here we offer an analysis of syntactic features to characterize general repetition in models, beyond frequent n-grams. Specifically, we define syntactic templates and show that models tend to produce templated text in downstream tasks at a higher rate than what is found in human-reference texts. We find that most (76%) templates in model-generated text can be found in pre-training data (compared to only 35% of human-authored text), and are not overwritten during fine-tuning processes such as RLHF. This connection to the pre-training data allows us to analyze syntactic templates in models where we do not have the pre-training data. We also find that templates as features are able to differentiate between models, tasks, and domains, and are useful for qualitatively evaluating common model constructions. Finally, we demonstrate the use of templates as a useful tool for analyzing style memorization of training data in LLMs.
Standardizing the Measurement of Text Diversity: A Tool and a Comparative Analysis of Scores
Mar 01, 2024



The diversity across outputs generated by large language models shapes the perception of their quality and utility. Prompt leaks, templated answer structure, and canned responses across different interactions are readily noticed by people, but there is no standard score to measure this aspect of model behavior. In this work we empirically investigate diversity scores on English texts. We find that computationally efficient compression algorithms capture information similar to what is measured by slow to compute $n$-gram overlap homogeneity scores. Further, a combination of measures -- compression ratios, self-repetition of long $n$-grams and Self-BLEU and BERTScore -- are sufficient to report, as they have low mutual correlation with each other. The applicability of scores extends beyond analysis of generative models; for example, we highlight applications on instruction-tuning datasets and human-produced texts. We release a diversity score package to facilitate research and invite consistency across reports.
How Much Annotation is Needed to Compare Summarization Models?
Feb 28, 2024



Modern instruction-tuned models have become highly capable in text generation tasks such as summarization, and are expected to be released at a steady pace. In practice one may now wish to choose confidently, but with minimal effort, the best performing summarization model when applied to a new domain or purpose. In this work, we empirically investigate the test sample size necessary to select a preferred model in the context of news summarization. Empirical results reveal that comparative evaluation converges quickly for both automatic and human evaluation, with clear preferences for a system emerging from under 100 examples. The human preference data allows us to quantify how well automatic scores can reproduce preference rankings across a variety of downstream summarization tasks. We find that, while automatic metrics are stable at smaller sample sizes, only some automatic metrics are able to moderately predict model win rates according to human preference.
Evaluating the Zero-shot Robustness of Instruction-tuned Language Models
Jul 09, 2023



Instruction fine-tuning has recently emerged as a promising approach for improving the zero-shot capabilities of Large Language Models (LLMs) on new tasks. This technique has shown particular strength in improving the performance of modestly sized LLMs, sometimes inducing performance competitive with much larger model variants. In this paper we ask two questions: (1) How sensitive are instruction-tuned models to the particular phrasings of instructions, and, (2) How can we make them more robust to such natural language variation? To answer the former, we collect a set of 319 instructions manually written by NLP practitioners for over 80 unique tasks included in widely used benchmarks, and we evaluate the variance and average performance of these instructions as compared to instruction phrasings observed during instruction fine-tuning. We find that using novel (unobserved) but appropriate instruction phrasings consistently degrades model performance, sometimes substantially so. Further, such natural instructions yield a wide variance in downstream performance, despite their semantic equivalence. Put another way, instruction-tuned models are not especially robust to instruction re-phrasings. We propose a simple method to mitigate this issue by introducing ``soft prompt'' embedding parameters and optimizing these to maximize the similarity between representations of semantically equivalent instructions. We show that this method consistently improves the robustness of instruction-tuned models.
Summarizing, Simplifying, and Synthesizing Medical Evidence Using GPT-3 (with Varying Success)
May 11, 2023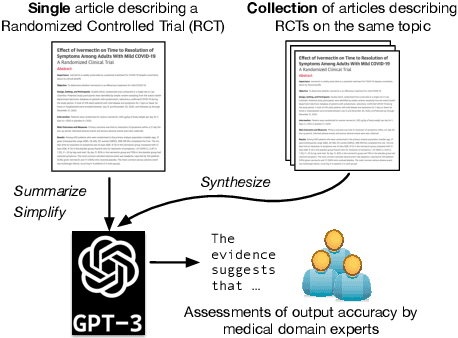

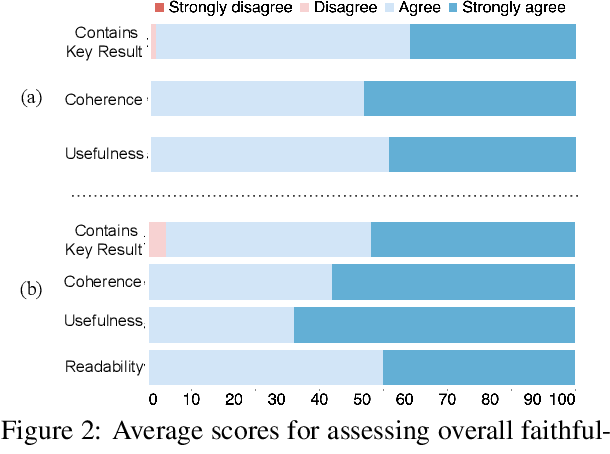

Large language models, particularly GPT-3, are able to produce high quality summaries of general domain news articles in few- and zero-shot settings. However, it is unclear if such models are similarly capable in more specialized, high-stakes domains such as biomedicine. In this paper, we enlist domain experts (individuals with medical training) to evaluate summaries of biomedical articles generated by GPT-3, given zero supervision. We consider both single- and multi-document settings. In the former, GPT-3 is tasked with generating regular and plain-language summaries of articles describing randomized controlled trials; in the latter, we assess the degree to which GPT-3 is able to \emph{synthesize} evidence reported across a collection of articles. We design an annotation scheme for evaluating model outputs, with an emphasis on assessing the factual accuracy of generated summaries. We find that while GPT-3 is able to summarize and simplify single biomedical articles faithfully, it struggles to provide accurate aggregations of findings over multiple documents. We release all data and annotations used in this work.