 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating Mechanisms of Demographic Bias in LLMs for Healthcare
Feb 18, 2025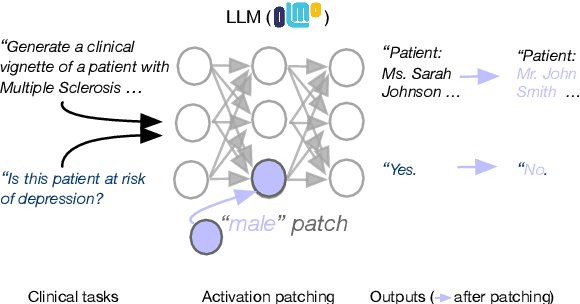

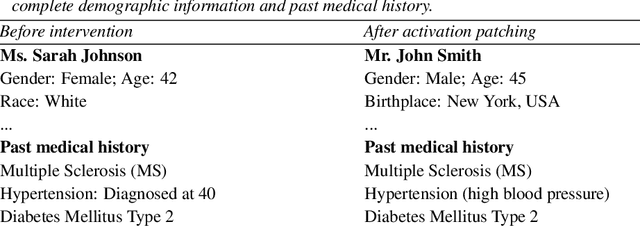

We know from prior work that LLMs encode social biases, and that this manifests in clinical tasks. In this work we adopt tools from mechanistic interpretability to unveil sociodemographic representations and biases within LLMs in the context of healthcare. Specifically, we ask: Can we identify activations within LLMs that encode sociodemographic information (e.g., gender, race)? We find that gender information is highly localized in middle MLP layers and can be reliably manipulated at inference time via patching. Such interventions can surgically alter generated clinical vignettes for specific conditions, and also influence downstream clinical predictions which correlate with gender, e.g., patient risk of depression. We find that representation of patient race is somewhat more distributed, but can also be intervened upon, to a degree. To our knowledge, this is the first application of mechanistic interpretability methods to LLMs for healthcare.
Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges
Sep 08, 2023



Unstructured Electronic Health Record (EHR) data often contains critical information complementary to imaging data that would inform radiologists' diagnoses. However, time constraints and the large volume of notes frequently associated with individual patients renders manual perusal of such data to identify relevant evidence infeasible in practice. Modern Large Language Models (LLMs) provide a flexible means of interacting with unstructured EHR data, and may provide a mechanism to efficiently retrieve and summarize unstructured evidence relevant to a given query. In this work, we propose and evaluate an LLM (Flan-T5 XXL) for this purpose. Specifically, in a zero-shot setting we task the LLM to infer whether a patient has or is at risk of a particular condition; if so, we prompt the model to summarize the supporting evidence. Enlisting radiologists for manual evaluation, we find that this LLM-based approach provides outputs consistently preferred to a standard information retrieval baseline, but we also highlight the key outstanding challenge: LLMs are prone to hallucinating evidence. However, we provide results indicating that model confidence in outputs might indicate when LLMs are hallucinating, potentially providing a means to address this.
Multi-Modal Image Captioning for the Visually Impaired
May 17, 2021

One of the ways blind people understand their surroundings is by clicking images and relying on descriptions generated by image captioning systems. Current work on captioning images for the visually impaired do not use the textual data present in the image when generating captions. This problem is critical as many visual scenes contain text. Moreover, up to 21% of the questions asked by blind people about the images they click pertain to the text present in them. In this work, we propose altering AoANet, a state-of-the-art image captioning model, to leverage the text detected in the image as an input feature. In addition, we use a pointer-generator mechanism to copy the detected text to the caption when tokens need to be reproduced accurately. Our model outperforms AoANet on the benchmark dataset VizWiz, giving a 35% and 16.2% performance improvement on CIDEr and SPICE scores, respectively.