 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating Mechanisms of Demographic Bias in LLMs for Healthcare
Paper and Code
Feb 18, 2025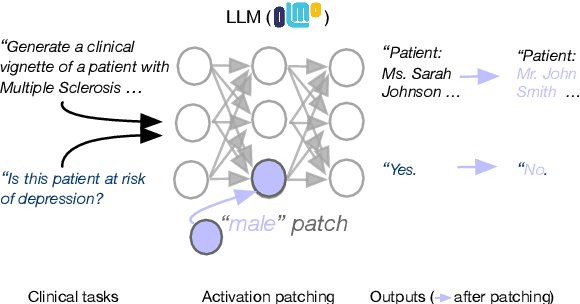

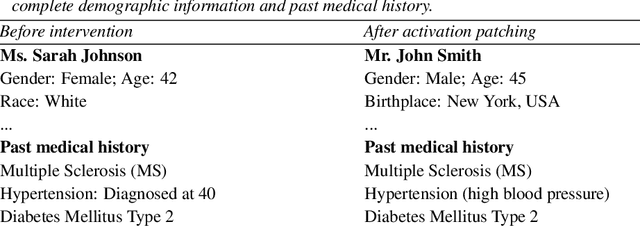

We know from prior work that LLMs encode social biases, and that this manifests in clinical tasks. In this work we adopt tools from mechanistic interpretability to unveil sociodemographic representations and biases within LLMs in the context of healthcare. Specifically, we ask: Can we identify activations within LLMs that encode sociodemographic information (e.g., gender, race)? We find that gender information is highly localized in middle MLP layers and can be reliably manipulated at inference time via patching. Such interventions can surgically alter generated clinical vignettes for specific conditions, and also influence downstream clinical predictions which correlate with gender, e.g., patient risk of depression. We find that representation of patient race is somewhat more distributed, but can also be intervened upon, to a degree. To our knowledge, this is the first application of mechanistic interpretability methods to LLMs for healthcare.