 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Large-scale Evaluation of Embedding Models for Knowledge Graph Completion
Apr 11, 2025Knowledge graph embedding (KGE) models are extensively studied for knowledge graph completion, yet their evaluation remains constrained by unrealistic benchmarks. Commonly used datasets are either faulty or too small to reflect real-world data. Few studies examine the role of mediator nodes, which are essential for modeling n-ary relationships, or investigate model performance variation across domains. Standard evaluation metrics rely on the closed-world assumption, which penalizes models for correctly predicting missing triples, contradicting the fundamental goals of link prediction. These metrics often compress accuracy assessment into a single value, obscuring models' specific strengths and weaknesses. The prevailing evaluation protocol operates under the unrealistic assumption that an entity's properties, for which values are to be predicted, are known in advance. While alternative protocols such as property prediction, entity-pair ranking and triple classification address some of these limitations, they remain underutilized. This paper conducts a comprehensive evaluation of four representative KGE models on large-scale datasets FB-CVT-REV and FB+CVT-REV. Our analysis reveals critical insights, including substantial performance variations between small and large datasets, both in relative rankings and absolute metrics, systematic overestimation of model capabilities when n-ary relations are binarized, and fundamental limitations in current evaluation protocols and metrics.
Realistic Re-evaluation of Knowledge Graph Completion Methods: An Experimental Study
Mar 18, 2020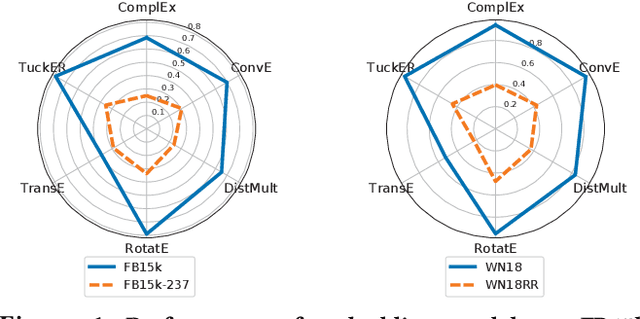
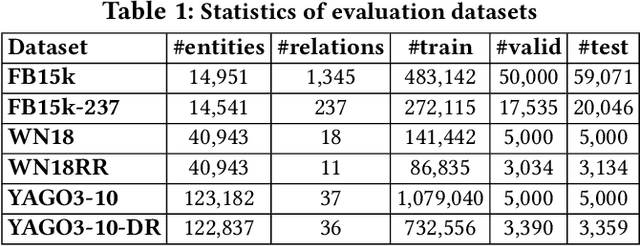
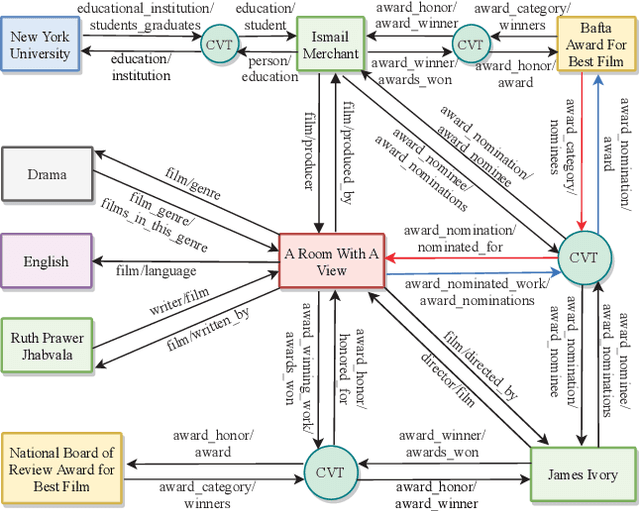

In the active research area of employing embedding models for knowledge graph completion, particularly for the task of link prediction, most prior studies used two benchmark datasets FB15k and WN18 in evaluating such models. Most triples in these and other datasets in such studies belong to reverse and duplicate relations which exhibit high data redundancy due to semantic duplication, correlation or data incompleteness. This is a case of excessive data leakage---a model is trained using features that otherwise would not be available when the model needs to be applied for real prediction. There are also Cartesian product relations for which every triple formed by the Cartesian product of applicable subjects and objects is a true fact. Link prediction on the aforementioned relations is easy and can be achieved with even better accuracy using straightforward rules instead of sophisticated embedding models. A more fundamental defect of these models is that the link prediction scenario, given such data, is non-existent in the real-world. This paper is the first systematic study with the main objective of assessing the true effectiveness of embedding models when the unrealistic triples are removed. Our experiment results show these models are much less accurate than what we used to perceive. Their poor accuracy renders link prediction a task without truly effective automated solution. Hence, we call for re-investigation of possible effective approaches.
A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs
Mar 10, 2020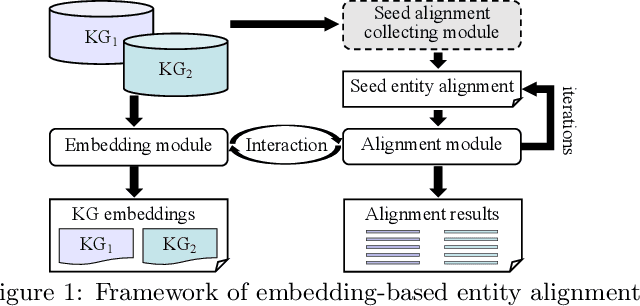
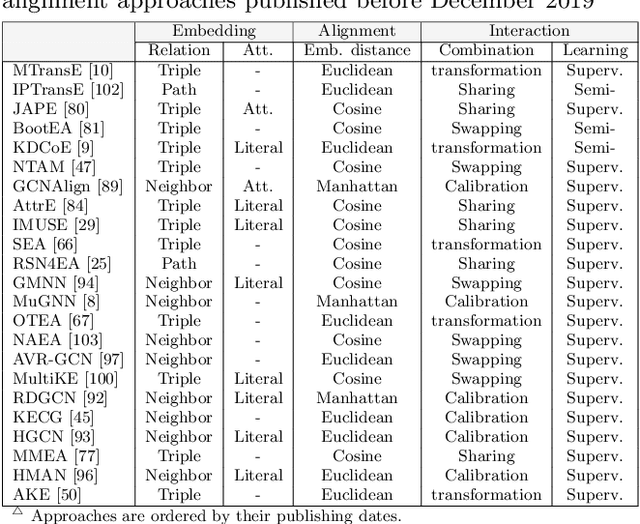
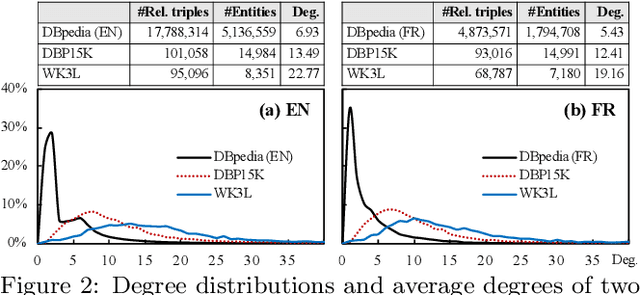
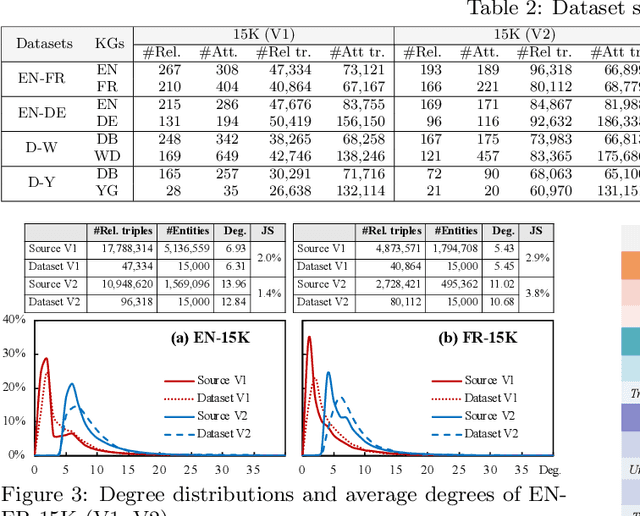
Entity alignment seeks to find entities in different knowledge graphs (KGs) that refer to the same real-world object. Recent advancement in KG embedding impels the advent of embedding-based entity alignment, which encodes entities in a continuous embedding space and measures entity similarities based on the learned embeddings. In this paper, we conduct a comprehensive experimental study of this emerging field. This study surveys 23 recent embedding-based entity alignment approaches and categorizes them based on their techniques and characteristics. We further observe that current approaches use different datasets in evaluation, and the degree distributions of entities in these datasets are inconsistent with real KGs. Hence, we propose a new KG sampling algorithm, with which we generate a set of dedicated benchmark datasets with various heterogeneity and distributions for a realistic evaluation. This study also produces an open-source library, which includes 12 representative embedding-based entity alignment approaches. We extensively evaluate these approaches on the generated datasets, to understand their strengths and limitations. Additionally, for several directions that have not been explored in current approaches, we perform exploratory experiments and report our preliminary findings for future studies. The benchmark datasets, open-source library and experimental results are all accessible online and will be duly maintained.