 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
Paper and Code
May 10, 2022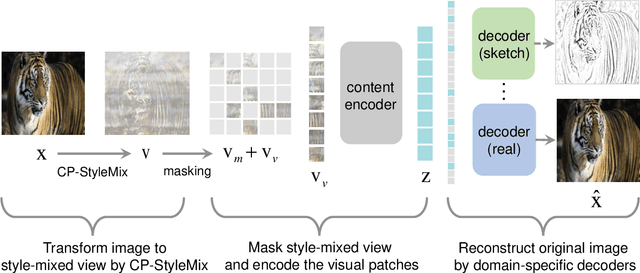

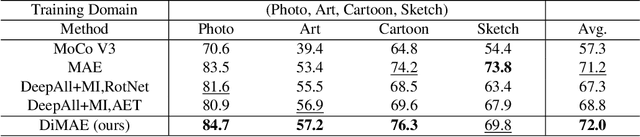
Generalizing learned representations across significantly different visual domains is a fundamental yet crucial ability of the human visual system. While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain. Therefore, the self-supervised learning from multiple domains task is proposed to learn domain-invariant features that are not only suitable for evaluation on the same domain as the training set but also can be generalized to unseen domains. In this paper, we propose a Domain-invariant Masked AutoEncoder (DiMAE) for self-supervised learning from multi-domains, which designs a new pretext task, \emph{i.e.,} the cross-domain reconstruction task, to learn domain-invariant features. The core idea is to augment the input image with style noise from different domains and then reconstruct the image from the embedding of the augmented image, regularizing the encoder to learn domain-invariant features. To accomplish the idea, DiMAE contains two critical designs, 1) content-preserved style mix, which adds style information from other domains to input while persevering the content in a parameter-free manner, and 2) multiple domain-specific decoders, which recovers the corresponding domain style of input to the encoded domain-invariant features for reconstruction. Experiments on PACS and DomainNet illustrate that DiMAE achieves considerable gains compared with recent state-of-the-art methods.