 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-sensitive Information Retention for Accurate Binary Neural Network
Paper and Code
Sep 25, 2021

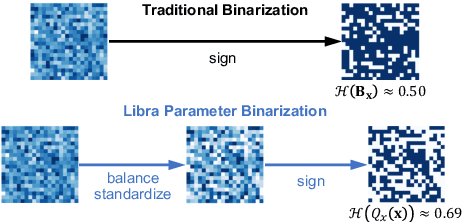

Model binarization is an effective method of compressing neural networks and accelerating their inference process, which enables state-of-the-art models to run on resource-limited devices. However, a significant performance gap still exists between the 1-bit model and the 32-bit one. The empirical study shows that binarization causes a great loss of information in the forward and backward propagation which harms the performance of binary neural networks (BNNs), and the limited information representation ability of binarized parameter is one of the bottlenecks of BNN performance. We present a novel Distribution-sensitive Information Retention Network (DIR-Net) to retain the information of the forward activations and backward gradients, which improves BNNs by distribution-sensitive optimization without increasing the overhead in the inference process. The DIR-Net mainly relies on two technical contributions: (1) Information Maximized Binarization (IMB): minimizing the information loss and the quantization error of weights/activations simultaneously by balancing and standardizing the weight distribution in the forward propagation; (2) Distribution-sensitive Two-stage Estimator (DTE): minimizing the information loss of gradients by gradual distribution-sensitive approximation of the sign function in the backward propagation, jointly considering the updating capability and accurate gradient. The DIR-Net investigates both forward and backward processes of BNNs from the unified information perspective, thereby provides new insight into the mechanism of network binarization. Comprehensive experiments on CIFAR-10 and ImageNet datasets show our DIR-Net consistently outperforms the SOTA binarization approaches under mainstream and compact architectures. Additionally, we conduct our DIR-Net on real-world resource-limited devices which achieves 11.1 times storage saving and 5.4 times speedup.