 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Clinically Informed Coarse-to-Fine Framework for Longitudinal CT Registration in Proton Therapy
Apr 15, 2026Proton therapy offers superior organ-at-risk sparing but is highly sensitive to anatomical changes, making accurate deformable image registration (DIR) across longitudinal CT scans essential. Conventional DIR methods are often too slow for emerging online adaptive workflows, while existing deep learning-based approaches are primarily designed for generic benchmarks and underutilize clinically relevant information beyond images. To address this gap, we propose a clinically scalable coarse-to-fine deformable registration framework that integrates multimodal information from the proton radiotherapy workflow to accommodate diverse clinical scenarios. The model employs dual CNN-based encoders for hierarchical feature extraction and a transformer-based decoder to progressively refine deformation fields. Beyond CT intensities, clinically critical priors, including target and organ-at-risk contours, dose distributions, and treatment planning text, are incorporated through anatomy- and risk-guided attention, text-conditioned feature modulation, and foreground-aware optimization, enabling anatomically focused and clinically informed deformation estimation. We evaluate the proposed framework on a large-scale proton therapy DIR dataset comprising 1,222 paired planning and repeat CT scans across multiple anatomical regions and disease types. Extensive experiments demonstrate consistent improvements over state-of-the-art methods, enabling fast and robust clinically meaningful registration.
Diffusion Transformer-based Universal Dose Denoising for Pencil Beam Scanning Proton Therapy
Jun 04, 2025Purpose: Intensity-modulated proton therapy (IMPT) offers precise tumor coverage while sparing organs at risk (OARs) in head and neck (H&N) cancer. However, its sensitivity to anatomical changes requires frequent adaptation through online adaptive radiation therapy (oART), which depends on fast, accurate dose calculation via Monte Carlo (MC) simulations. Reducing particle count accelerates MC but degrades accuracy. To address this, denoising low-statistics MC dose maps is proposed to enable fast, high-quality dose generation. Methods: We developed a diffusion transformer-based denoising framework. IMPT plans and 3D CT images from 80 H&N patients were used to generate noisy and high-statistics dose maps using MCsquare (1 min and 10 min per plan, respectively). Data were standardized into uniform chunks with zero-padding, normalized, and transformed into quasi-Gaussian distributions. Testing was done on 10 H&N, 10 lung, 10 breast, and 10 prostate cancer cases, preprocessed identically. The model was trained with noisy dose maps and CT images as input and high-statistics dose maps as ground truth, using a combined loss of mean square error (MSE), residual loss, and regional MAE (focusing on top/bottom 10% dose voxels). Performance was assessed via MAE, 3D Gamma passing rate, and DVH indices. Results: The model achieved MAEs of 0.195 (H&N), 0.120 (lung), 0.172 (breast), and 0.376 Gy[RBE] (prostate). 3D Gamma passing rates exceeded 92% (3%/2mm) across all sites. DVH indices for clinical target volumes (CTVs) and OARs closely matched the ground truth. Conclusion: A diffusion transformer-based denoising framework was developed and, though trained only on H&N data, generalizes well across multiple disease sites.
Benchmarking a foundation LLM on its ability to re-label structure names in accordance with the AAPM TG-263 report
Oct 05, 2023



Purpose: To introduce the concept of using large language models (LLMs) to re-label structure names in accordance with the American Association of Physicists in Medicine (AAPM) Task Group (TG)-263 standard, and to establish a benchmark for future studies to reference. Methods and Materials: The Generative Pre-trained Transformer (GPT)-4 application programming interface (API) was implemented as a Digital Imaging and Communications in Medicine (DICOM) storage server, which upon receiving a structure set DICOM file, prompts GPT-4 to re-label the structure names of both target volumes and normal tissues according to the AAPM TG-263. Three disease sites, prostate, head and neck, and thorax were selected for evaluation. For each disease site category, 150 patients were randomly selected for manually tuning the instructions prompt (in batches of 50) and 50 patients were randomly selected for evaluation. Structure names that were considered were those that were most likely to be relevant for studies utilizing structure contours for many patients. Results: The overall re-labeling accuracy of both target volumes and normal tissues for prostate, head and neck, and thorax cases was 96.0%, 98.5%, and 96.9% respectively. Re-labeling of target volumes was less accurate on average except for prostate - 100%, 93.1%, and 91.1% respectively. Conclusions: Given the accuracy of GPT-4 in re-labeling structure names of both target volumes and normal tissues as presented in this work, LLMs are poised to be the preferred method for standardizing structure names in radiation oncology, especially considering the rapid advancements in LLM capabilities that are likely to continue.
Deep-Learning-based Fast and Accurate 3D CT Deformable Image Registration in Lung Cancer
Apr 21, 2023Purpose: In some proton therapy facilities, patient alignment relies on two 2D orthogonal kV images, taken at fixed, oblique angles, as no 3D on-the-bed imaging is available. The visibility of the tumor in kV images is limited since the patient's 3D anatomy is projected onto a 2D plane, especially when the tumor is behind high-density structures such as bones. This can lead to large patient setup errors. A solution is to reconstruct the 3D CT image from the kV images obtained at the treatment isocenter in the treatment position. Methods: An asymmetric autoencoder-like network built with vision-transformer blocks was developed. The data was collected from 1 head and neck patient: 2 orthogonal kV images (1024x1024 voxels), 1 3D CT with padding (512x512x512) acquired from the in-room CT-on-rails before kVs were taken and 2 digitally-reconstructed-radiograph (DRR) images (512x512) based on the CT. We resampled kV images every 8 voxels and DRR and CT every 4 voxels, thus formed a dataset consisting of 262,144 samples, in which the images have a dimension of 128 for each direction. In training, both kV and DRR images were utilized, and the encoder was encouraged to learn the jointed feature map from both kV and DRR images. In testing, only independent kV images were used. The full-size synthetic CT (sCT) was achieved by concatenating the sCTs generated by the model according to their spatial information. The image quality of the synthetic CT (sCT) was evaluated using mean absolute error (MAE) and per-voxel-absolute-CT-number-difference volume histogram (CDVH). Results: The model achieved a speed of 2.1s and a MAE of <40HU. The CDVH showed that <5% of the voxels had a per-voxel-absolute-CT-number-difference larger than 185 HU. Conclusion: A patient-specific vision-transformer-based network was developed and shown to be accurate and efficient to reconstruct 3D CT images from kV images.
Evaluating Large Language Models on a Highly-specialized Topic, Radiation Oncology Physics
Apr 01, 2023We present the first study to investigate Large Language Models (LLMs) in answering radiation oncology physics questions. Because popular exams like AP Physics, LSAT, and GRE have large test-taker populations and ample test preparation resources in circulation, they may not allow for accurately assessing the true potential of LLMs. This paper proposes evaluating LLMs on a highly-specialized topic, radiation oncology physics, which may be more pertinent to scientific and medical communities in addition to being a valuable benchmark of LLMs. We developed an exam consisting of 100 radiation oncology physics questions based on our expertise at Mayo Clinic. Four LLMs, ChatGPT (GPT-3.5), ChatGPT (GPT-4), Bard (LaMDA), and BLOOMZ, were evaluated against medical physicists and non-experts. ChatGPT (GPT-4) outperformed all other LLMs as well as medical physicists, on average. The performance of ChatGPT (GPT-4) was further improved when prompted to explain first, then answer. ChatGPT (GPT-3.5 and GPT-4) showed a high level of consistency in its answer choices across a number of trials, whether correct or incorrect, a characteristic that was not observed in the human test groups. In evaluating ChatGPTs (GPT-4) deductive reasoning ability using a novel approach (substituting the correct answer with "None of the above choices is the correct answer."), ChatGPT (GPT-4) demonstrated surprising accuracy, suggesting the potential presence of an emergent ability. Finally, although ChatGPT (GPT-4) performed well overall, its intrinsic properties did not allow for further improvement when scoring based on a majority vote across trials. In contrast, a team of medical physicists were able to greatly outperform ChatGPT (GPT-4) using a majority vote. This study suggests a great potential for LLMs to work alongside radiation oncology experts as highly knowledgeable assistants.
AdvFoolGen: Creating Persistent Troubles for Deep Classifiers
Jul 20, 2020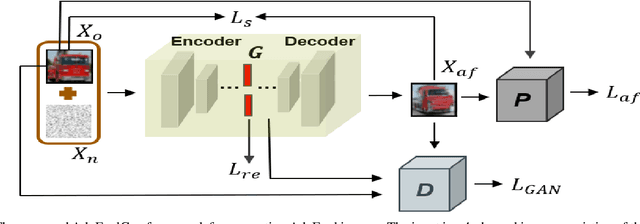
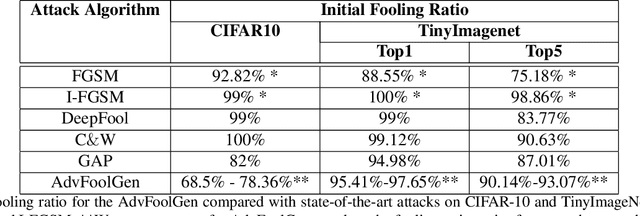

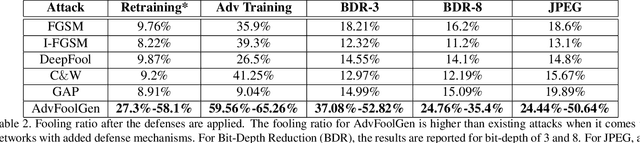
Researches have shown that deep neural networks are vulnerable to malicious attacks, where adversarial images are created to trick a network into misclassification even if the images may give rise to totally different labels by human eyes. To make deep networks more robust to such attacks, many defense mechanisms have been proposed in the literature, some of which are quite effective for guarding against typical attacks. In this paper, we present a new black-box attack termed AdvFoolGen, which can generate attacking images from the same feature space as that of the natural images, so as to keep baffling the network even though state-of-the-art defense mechanisms have been applied. We systematically evaluate our model by comparing with well-established attack algorithms. Through experiments, we demonstrate the effectiveness and robustness of our attack in the face of state-of-the-art defense techniques and unveil the potential reasons for its effectiveness through principled analysis. As such, AdvFoolGen contributes to understanding the vulnerability of deep networks from a new perspective and may, in turn, help in developing and evaluating new defense mechanisms.
Evaluating a Simple Retraining Strategy as a Defense Against Adversarial Attacks
Jul 20, 2020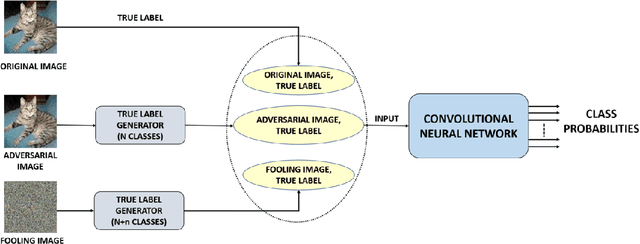
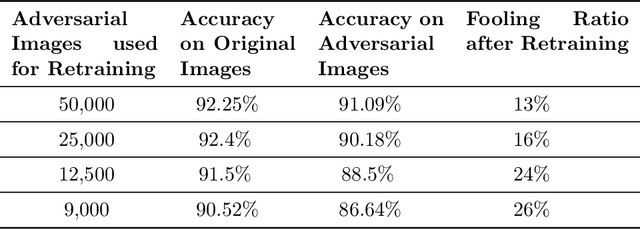
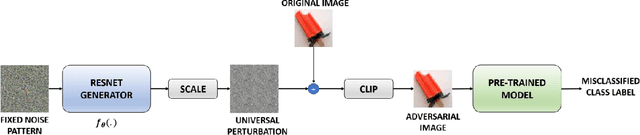

Though deep neural networks (DNNs) have shown superiority over other techniques in major fields like computer vision, natural language processing, robotics, recently, it has been proven that they are vulnerable to adversarial attacks. The addition of a simple, small and almost invisible perturbation to the original input image can be used to fool DNNs into making wrong decisions. With more attack algorithms being designed, a need for defending the neural networks from such attacks arises. Retraining the network with adversarial images is one of the simplest techniques. In this paper, we evaluate the effectiveness of such a retraining strategy in defending against adversarial attacks. We also show how simple algorithms like KNN can be used to determine the labels of the adversarial images needed for retraining. We present the results on two standard datasets namely, CIFAR-10 and TinyImageNet.
VSEC-LDA: Boosting Topic Modeling with Embedded Vocabulary Selection
Jan 15, 2020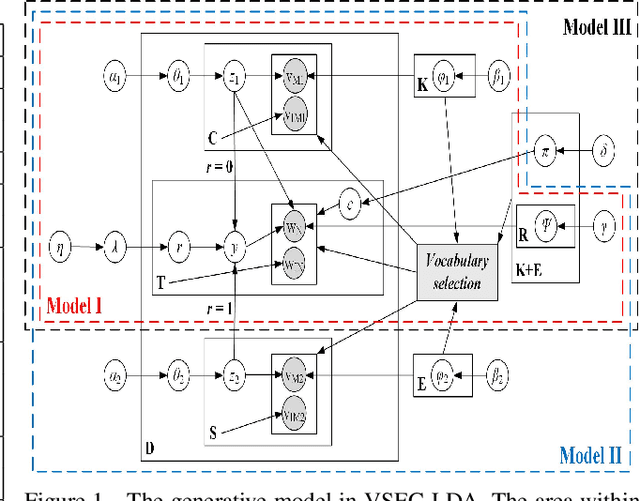
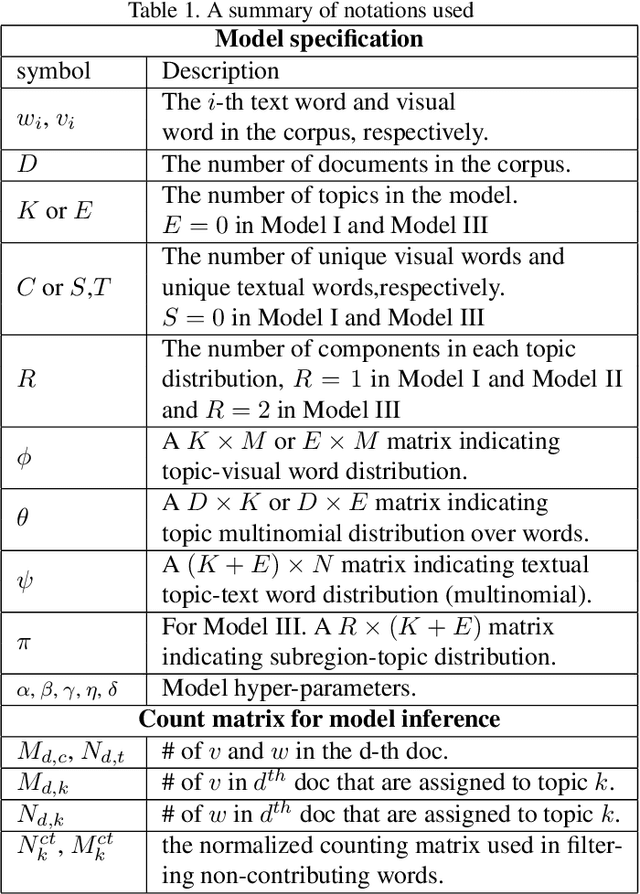

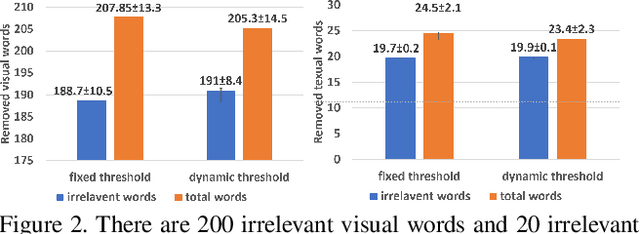
Topic modeling has found wide application in many problems where latent structures of the data are crucial for typical inference tasks. When applying a topic model, a relatively standard pre-processing step is to first build a vocabulary of frequent words. Such a general pre-processing step is often independent of the topic modeling stage, and thus there is no guarantee that the pre-generated vocabulary can support the inference of some optimal (or even meaningful) topic models appropriate for a given task, especially for computer vision applications involving "visual words". In this paper, we propose a new approach to topic modeling, termed Vocabulary-Selection-Embedded Correspondence-LDA (VSEC-LDA), which learns the latent model while simultaneously selecting most relevant words. The selection of words is driven by an entropy-based metric that measures the relative contribution of the words to the underlying model, and is done dynamically while the model is learned. We present three variants of VSEC-LDA and evaluate the proposed approach with experiments on both synthetic and real databases from different applications. The results demonstrate the effectiveness of built-in vocabulary selection and its importance in improving the performance of topic modeling.