 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAT: Pseudo-Adversarial Training For Detecting Adversarial Videos
Sep 13, 2021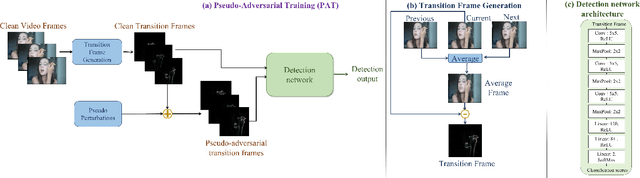
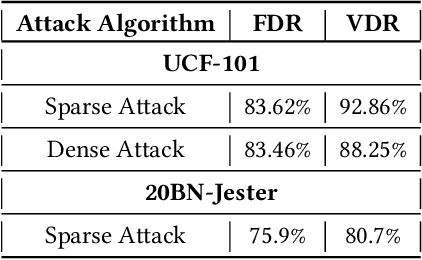

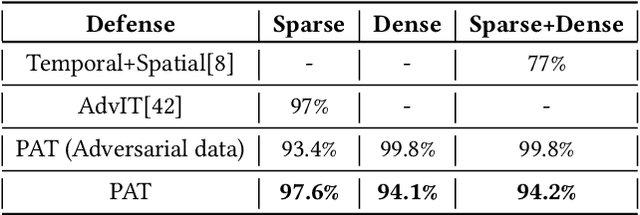
Extensive research has demonstrated that deep neural networks (DNNs) are prone to adversarial attacks. Although various defense mechanisms have been proposed for image classification networks, fewer approaches exist for video-based models that are used in security-sensitive applications like surveillance. In this paper, we propose a novel yet simple algorithm called Pseudo-Adversarial Training (PAT), to detect the adversarial frames in a video without requiring knowledge of the attack. Our approach generates `transition frames' that capture critical deviation from the original frames and eliminate the components insignificant to the detection task. To avoid the necessity of knowing the attack model, we produce `pseudo perturbations' to train our detection network. Adversarial detection is then achieved through the use of the detected frames. Experimental results on UCF-101 and 20BN-Jester datasets show that PAT can detect the adversarial video frames and videos with a high detection rate. We also unveil the potential reasons for the effectiveness of the transition frames and pseudo perturbations through extensive experiments.
AdvFoolGen: Creating Persistent Troubles for Deep Classifiers
Jul 20, 2020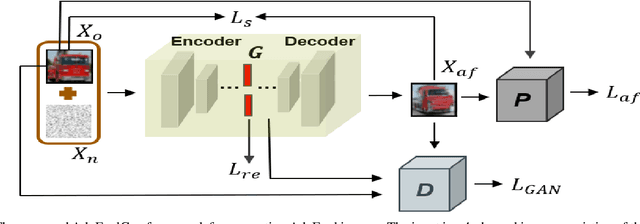
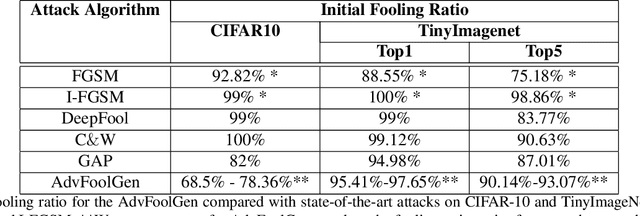

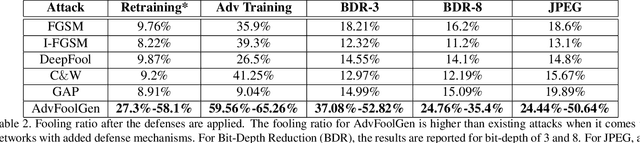
Researches have shown that deep neural networks are vulnerable to malicious attacks, where adversarial images are created to trick a network into misclassification even if the images may give rise to totally different labels by human eyes. To make deep networks more robust to such attacks, many defense mechanisms have been proposed in the literature, some of which are quite effective for guarding against typical attacks. In this paper, we present a new black-box attack termed AdvFoolGen, which can generate attacking images from the same feature space as that of the natural images, so as to keep baffling the network even though state-of-the-art defense mechanisms have been applied. We systematically evaluate our model by comparing with well-established attack algorithms. Through experiments, we demonstrate the effectiveness and robustness of our attack in the face of state-of-the-art defense techniques and unveil the potential reasons for its effectiveness through principled analysis. As such, AdvFoolGen contributes to understanding the vulnerability of deep networks from a new perspective and may, in turn, help in developing and evaluating new defense mechanisms.
Evaluating a Simple Retraining Strategy as a Defense Against Adversarial Attacks
Jul 20, 2020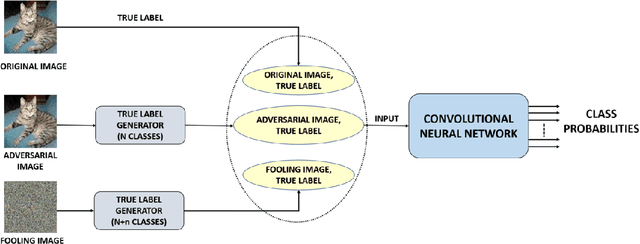
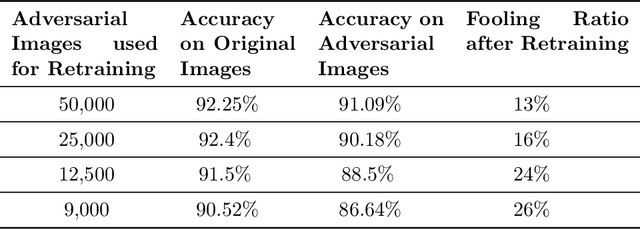
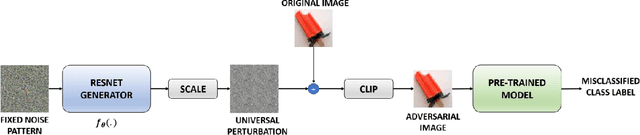

Though deep neural networks (DNNs) have shown superiority over other techniques in major fields like computer vision, natural language processing, robotics, recently, it has been proven that they are vulnerable to adversarial attacks. The addition of a simple, small and almost invisible perturbation to the original input image can be used to fool DNNs into making wrong decisions. With more attack algorithms being designed, a need for defending the neural networks from such attacks arises. Retraining the network with adversarial images is one of the simplest techniques. In this paper, we evaluate the effectiveness of such a retraining strategy in defending against adversarial attacks. We also show how simple algorithms like KNN can be used to determine the labels of the adversarial images needed for retraining. We present the results on two standard datasets namely, CIFAR-10 and TinyImageNet.