 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSJTU:Spatial judgments in multimodal models towards unified segmentation through coordinate detection
Paper and Code
Dec 03, 2024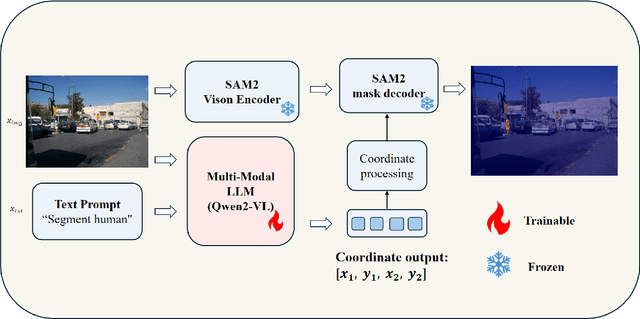
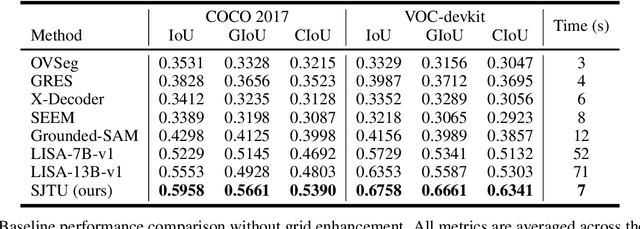
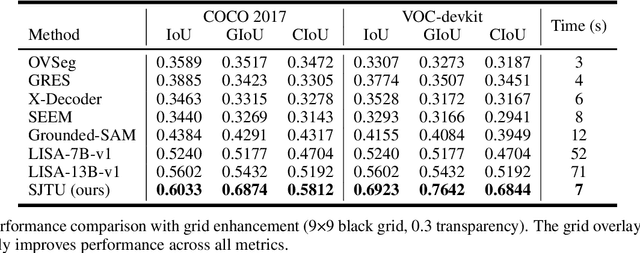
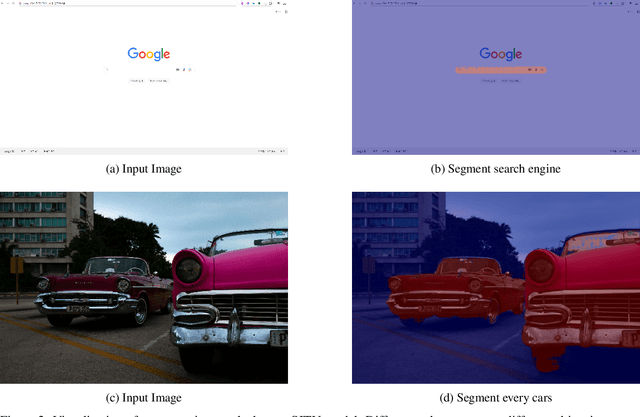
Despite advances in vision-language understanding, implementing image segmentation within multimodal architectures remains a fundamental challenge in modern artificial intelligence systems. Existing vision-language models, which primarily rely on backbone architectures or CLIP-based embedding learning, demonstrate inherent limitations in fine-grained spatial localization and operational capabilities. This paper introduces SJTU: Spatial Judgments in multimodal models - Towards Unified segmentation through coordinate detection, a novel framework that leverages spatial coordinate understanding to bridge vision-language interaction and precise segmentation, enabling accurate target identification through natural language instructions. The framework proposes a novel approach for integrating segmentation techniques with vision-language models based on multimodal spatial inference. By leveraging normalized coordinate detection for bounding boxes and translating it into actionable segmentation outputs, we explore the possibility of integrating multimodal spatial and language representations. Based on the proposed technical approach, the framework demonstrates superior performance on various benchmark datasets as well as accurate object segmentation. Results on the COCO 2017 dataset for general object detection and Pascal VOC datasets for semantic segmentation demonstrate the generalization capabilities of the framework.